[论文解读] SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
SyncDreamer 使用同步多视图扩散并结合 3D 感知特征注意力,从单一输入视图生成多视图一致的图像,从而在不产生视角不一致输出的前提下实现更好的 3D 重建。
In this paper, we present a novel diffusion model called that generates multiview-consistent images from a single-view image. Using pretrained large-scale 2D diffusion models, recent work Zero123 demonstrates the ability to generate plausible novel views from a single-view image of an object. However, maintaining consistency in geometry and colors for the generated images remains a challenge. To address this issue, we propose a synchronized multiview diffusion model that models the joint probability distribution of multiview images, enabling the generation of multiview-consistent images in a single reverse process. SyncDreamer synchronizes the intermediate states of all the generated images at every step of the reverse process through a 3D-aware feature attention mechanism that correlates the corresponding features across different views. Experiments show that SyncDreamer generates images with high consistency across different views, thus making it well-suited for various 3D generation tasks such as novel-view-synthesis, text-to-3D, and image-to-3D.
研究动机与目标
- 在任意对象上实现并促进鲁棒的单视图到多视图三维重建。
- 通过一个联合的多视图扩散模型,克服生成图像中的多视图不一致。
- 利用 3D 感知特征注意力机制在去噪过程中同步跨视图信息。
- 从预训练的二维扩散模型初始化,以保持对多样输入风格的泛化能力。
提出的方法
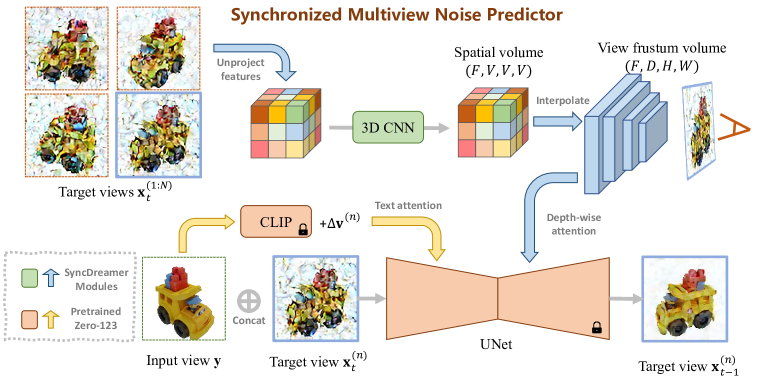
- 通过使用 N 个同步的噪声预测器,将扩散模型扩展为建模 N 个视图的联合分布。
- 使用一个从 Zero123(基于 Stable Diffusion)初始化的共享 UNet 作为所有视图的骨干网络。
- 引入 3D 感知特征注意力,在从全局空间体积推导出的视锥体上构建深度方向的注意力机制。
- 在每一步中对随机选择的视图的噪声进行预测的损失进行训练,从而实现跨视图的同步。
- 渲染一组固定的视角(N = 16),并在 Objaverse 数据上进行训练以学习跨视图一致性。
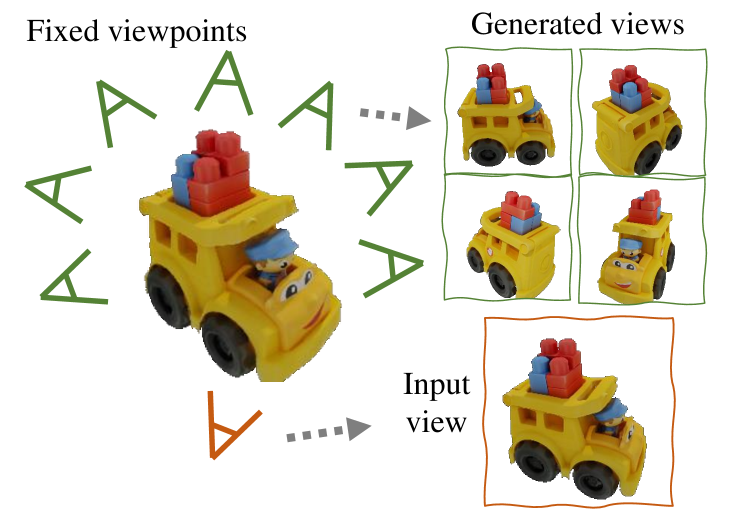
实验结果
研究问题
- RQ1扩散过程是否能被扩展为联合建模并同步多个视图,以从单个输入图像确保跨视图的一致性?
- RQ2如何在去噪过程中对跨视图信息进行编码与传播,以实现跨视图的几何和颜色一致性?
- RQ3从强大的二维扩散骨干网(Zero123)初始化是否能提高对任意对象和输入风格的对3D重建的泛化能力?
- RQ43D 感知注意力机制对多视图一致性以及下游的 3D 重建质量有什么影响?
主要发现
- SyncDreamer 在 Google Scanned Object 数据集上实现的多视图一致性和重建质量高于基线方法。
- 在新视图合成中,RealFusion、Zero123 和 SyncDreamer 分别达到 PSNR/SSIM/LPIPS 为 15.26/0.722/0.283、18.93/0.779/0.166、20.05/0.798/0.146,点数分别为 #Points 4010、95、1123。
- 在单视图重建中,SyncDreamer 达到 Chamfer Distance 0.0261 和 Volume IoU 0.5421,优于 RealFusion (0.0819, 0.2741) 和 Zero123 (0.0339, 0.5035)。
- 该方法通过改变种子,可以从同一输入生成多个合理的实例。
- 消融实验表明 3D 感知注意力的必要性以及以 Zero123 作为骨干网有助于在 2D 风格和绘画风格上的泛化。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。