[论文解读] Synthetic Data Generation with LLM for Improved Depression Prediction
论文提出一种链式推理提示管线,利用大型语言模型从 DAIC-WOZ 转录文本生成合成的摘要和情感数据,以扩充真实数据来改善抑郁程度预测,并解决隐私和数据不平衡问题。
Automatic detection of depression is a rapidly growing field of research at the intersection of psychology and machine learning. However, with its exponential interest comes a growing concern for data privacy and scarcity due to the sensitivity of such a topic. In this paper, we propose a pipeline for Large Language Models (LLMs) to generate synthetic data to improve the performance of depression prediction models. Starting from unstructured, naturalistic text data from recorded transcripts of clinical interviews, we utilize an open-source LLM to generate synthetic data through chain-of-thought prompting. This pipeline involves two key steps: the first step is the generation of the synopsis and sentiment analysis based on the original transcript and depression score, while the second is the generation of the synthetic synopsis/sentiment analysis based on the summaries generated in the first step and a new depression score. Not only was the synthetic data satisfactory in terms of fidelity and privacy-preserving metrics, it also balanced the distribution of severity in the training dataset, thereby significantly enhancing the model's capability in predicting the intensity of the patient's depression. By leveraging LLMs to generate synthetic data that can be augmented to limited and imbalanced real-world datasets, we demonstrate a novel approach to addressing data scarcity and privacy concerns commonly faced in automatic depression detection, all while maintaining the statistical integrity of the original dataset. This approach offers a robust framework for future mental health research and applications.
研究动机与目标
- 通过生成合成数据来解决文本抑郁检测中的数据稀缺性和隐私问题。
- 开发一个以抑郁评分为条件的两步摘要与情感分析生成过程。
- 评估合成数据在提高抑郁严重程度预测方面的保真度、效用和隐私性。
提出的方法
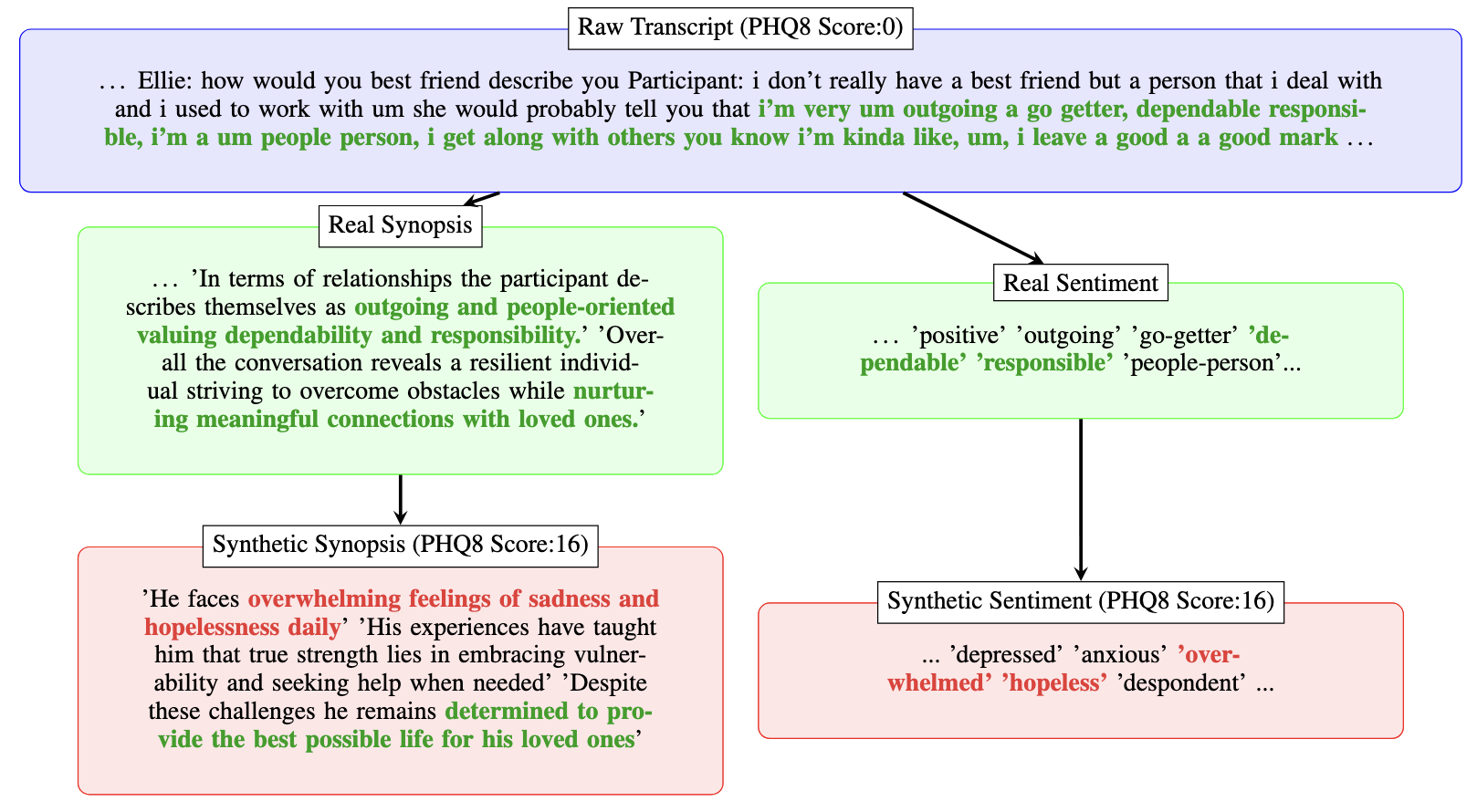
- 使用 Meta Llama 3.2-3B-Instruct 从原始转录文本生成初始摘要和情感分析。
- 应用链式思考提示,为一个新随机生成的 PHQ-8 分数创建合成摘要和情感分析。
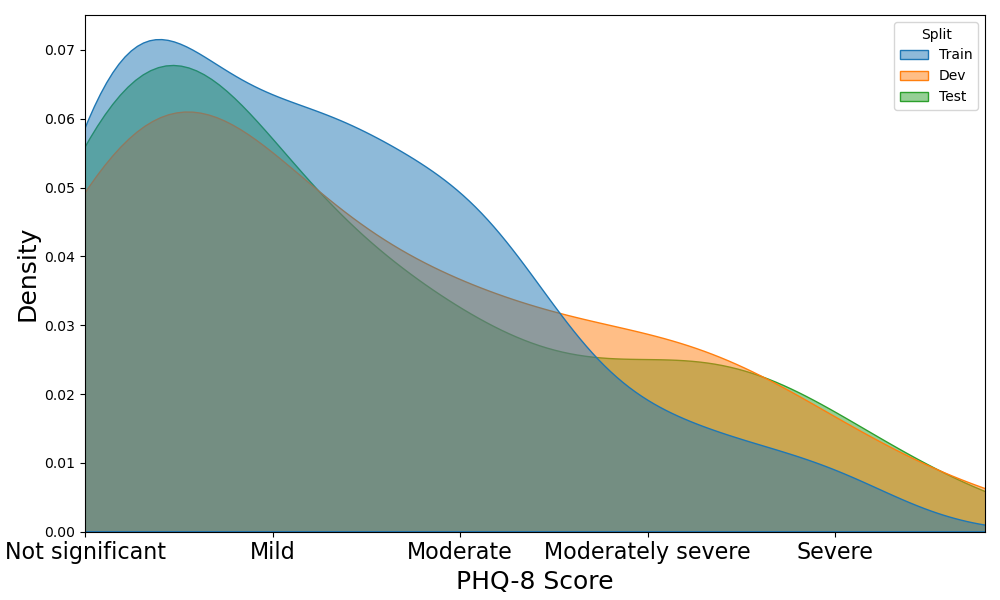
- 通过对合成数据中较高的 PHQ-8 分数进行过采样以平衡数据分布,降低偏斜。
- 在合成数据上训练模型,然后与真实数据结合以评估性能提升。
- 通过合成数据与真实数据的嵌入距离度量来评估隐私;用摘要嵌入的 PCA 可视化保真度。
实验结果
研究问题
- RQ1通过链式思考提示生成的合成数据在加入真实数据后,是否能改善抑郁严重程度的预测?
- RQ2基于摘要的合成文本是否保留原始数据的关键统计属性(保真度)并保护参与者隐私?
- RQ3与仅在真实数据上训练的模型相比,合成数据对模型训练有何影响?
- RQ4使用合成样本进行数据增强在处理 PHQ-8 分数的类别不平衡方面有何影响?
主要发现
- 单独的合成数据在 PHQ-8 分数预测中提供 RMSE 4.80 和 MAE 4.06,优于某些真实数据基线。
- 将原始数据与合成数据结合可获得最佳结果,RMSE 4.64,MAE 3.66。
- 在此设置中,基于组合数据训练的 BERT 模型优于随机森林和 GPT-4o 基线。
- 摘要嵌入的 PCA 显示原始数据与合成数据之间存在重叠,合成数据扩展到严重抑郁区域。
- 隐私分析显示 Real vs. Synthetic 的平均嵌入距离高于 Real vs. Real,表明与真实数据的差异性更大,隐私保护更好。
- 合成数据提高数据多样性,帮助平衡 PHQ-8 分数分布,从而提升模型性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。