[论文解读] T-RAG: Lessons from the LLM Trenches
本文提出 Tree-RAG (T-RAG),一种带有分层实体树的检索增强生成系统,并对私有治理文档的本地QA进行 finetuned Llama-2 7B,显示相比标准 RAG 和微调基线的准确性提升,以及经验教训。
Large Language Models (LLM) have shown remarkable language capabilities fueling attempts to integrate them into applications across a wide range of domains. An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, limited computational resources and the need for a robust application that correctly responds to queries. Retrieval-Augmented Generation (RAG) has emerged as the most prominent framework for building LLM-based applications. While building a RAG is relatively straightforward, making it robust and a reliable application requires extensive customization and relatively deep knowledge of the application domain. We share our experiences building and deploying an LLM application for question answering over private organizational documents. Our application combines the use of RAG with a finetuned open-source LLM. Additionally, our system, which we call Tree-RAG (T-RAG), uses a tree structure to represent entity hierarchies within the organization. This is used to generate a textual description to augment the context when responding to user queries pertaining to entities within the organization's hierarchy. Our evaluations, including a Needle in a Haystack test, show that this combination performs better than a simple RAG or finetuning implementation. Finally, we share some lessons learned based on our experiences building an LLM application for real-world use.
研究动机与目标
- 展示一个面向私有组织文档的真实世界基于大模型的问答系统。
- 展示将 RAG 与微调的开源大型语言模型结合,提升事实准确性和回答质量。
- 引入基于树的上下文(实体层级)以增强实体相关问题的回答。
- 提出一个新的评估指标(Correct-Verbose)以捕捉正确但过于冗长的回答。
- 分享将基于 LLM 的问答系统投入生产使用的实际经验教训。)
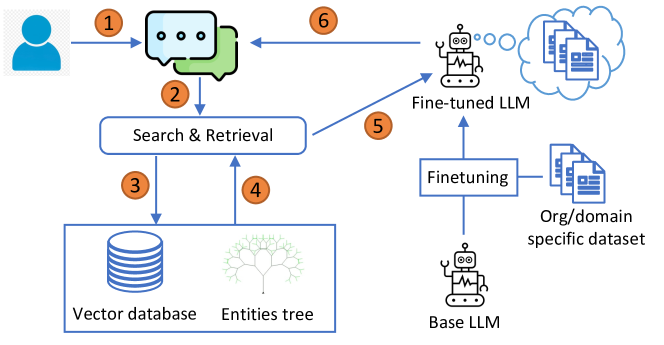
提出的方法
- 将 Retrieval-Augmented Generation (RAG) 与微调的开源 Llama-2 7B 集成,用于答案生成。
- 引入 Tree-RAG (T-RAG):在标准 RAG 上下文中加入编码组织层级的实体树。
- 从组织的治理文档生成指令数据集,并进行 PEFT (QLoRA) 与 4 位量化,对 LLM 进行微调。
- 使用向量存储(Chroma DB)来管理文档块,并通过 MM Retrieval 选择多样且相关的块。
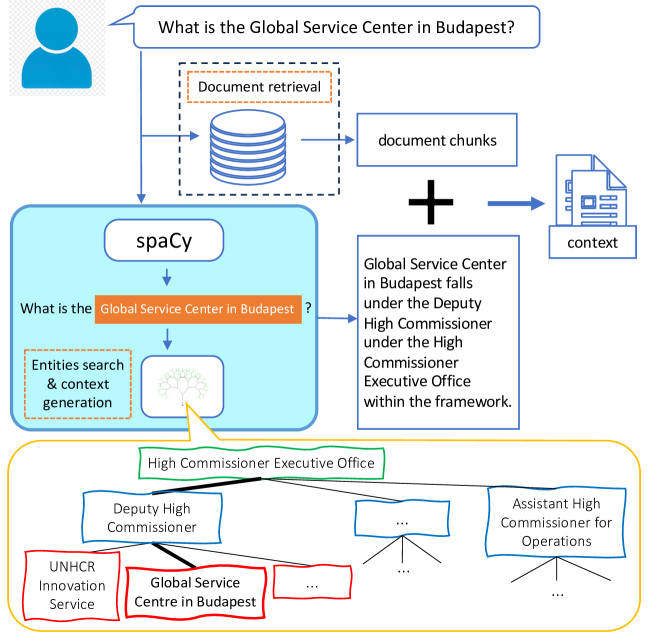
- 通过基于 spaCy 的命名实体识别,结合自定义组织特定规则,将关于查询中实体的文本陈述加入到检索上下文中。
- 将组织层级表示为树并对其进行查询,以提取实体-职位信息,在提及实体时扩充上下文。
- 使用人类评估,对正确(C)和正确-冗长(CV)回答进行打分。
实验结果
研究问题
- RQ1T-RAG 系统是否在企业文档问答中比标准 RAG 或单独微调模型在事实准确性和相关性方面有所提升?
- RQ2增加实体树上下文对性能的影响如何,特别是对于复杂的实体相关问题?
- RQ3当上下文受限或在利用实体层级时,微调的 LLM 与 RAG 的比较如何?
- RQ4提出的 Correct-Verbose 指标是否能为系统之间提供有意义的区分?
主要发现
| Question Set | N | C | CV | T | Perc. | |
|---|---|---|---|---|---|---|
| RAG | set 1 | 17 | 9 | 0 | 9 | 52.9% |
| RAG | set 2 | 11 | 7 | 0 | 7 | 63.6% |
| RAG | set 3 | 9 | 4 | 1 | 5 | 55.6% |
| RAG | All | 37 | 20 | 1 | 21 | 56.8% |
| Finetuned | set 1 | 17 | 11 | 1 | 12 | 70.6% |
| Finetuned | set 2 | 11 | 3 | 0 | 3 | 27.3% |
| Finetuned | set 3 | 9 | 5 | 0 | 5 | 55.6% |
| Finetuned | All | 37 | 19 | 1 | 20 | 54.1% |
| T-RAG | set 1 | 17 | 9 | 4 | 13 | 76.5% |
| T-RAG | set 2 | 11 | 6 | 2 | 8 | 72.7% |
| T-RAG | set 3 | 9 | 6 | 0 | 6 | 66.7% |
| T-RAG | All | 37 | 21 | 6 | 27 | 73.0% |
- T-RAG 总体上在正确或正确-冗长回答方面达到更高的比例(27/37),高于 RAG(21/37)或微调(20/37)。
- 树形上下文显著提高实体相关问题的准确性,尤其是复杂查询。
- 将实体树上下文与微调的 Llama-2 结合可带来显著提升(例如,简单问题从 8/17 提升到 17/17;复杂问题从 8/22 提升到 15/22)。
- 在带有实体树上下文的 RAG 能减少幻觉和实体在组织类别中的错位。
- T-RAG 展现出更冗长的正确答案(CV),但在总体上对一组问题更正确。
- 评估使用了三组用户问题集,人工打分(C 或 CV)。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。