[论文解读] Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
Step-Back Prompting uses abstraction to derive high-level concepts and first principles, grounding reasoning to improve multi-task performance in STEM, Knowledge QA, and multi-hop reasoning, achieving notable gains over baselines and CoT prompting.
We present Step-Back Prompting, a simple prompting technique that enables LLMs to do abstractions to derive high-level concepts and first principles from instances containing specific details. Using the concepts and principles to guide reasoning, LLMs significantly improve their abilities in following a correct reasoning path towards the solution. We conduct experiments of Step-Back Prompting with PaLM-2L, GPT-4 and Llama2-70B models, and observe substantial performance gains on various challenging reasoning-intensive tasks including STEM, Knowledge QA, and Multi-Hop Reasoning. For instance, Step-Back Prompting improves PaLM-2L performance on MMLU (Physics and Chemistry) by 7% and 11% respectively, TimeQA by 27%, and MuSiQue by 7%.
研究动机与目标
- 激励大型语言模型在复杂、细节丰富的推理方面的挑战。
- 提出 Step-Back Prompting,在解决问题之前推导高层抽象概念。
- 证明基于抽象导向的推理能够提升在 STEM、知识问答和多跳任务中的准确性。
提出的方法
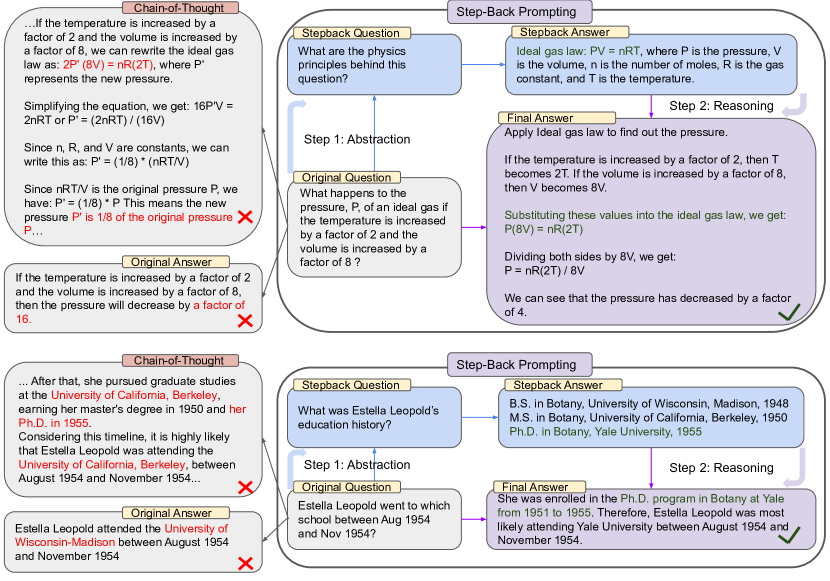
- Two-step Abstraction-and-Reasoning:先推导高层概念或原理,然后在这些抽象之上进行求解。
- 使用少样本演示来教导大模型抽象步骤。
- 在适当时利用检索增强(RAG)将高层概念与支持事实联系起来。
- 在多样数据集(STEM、知识问答、多跳)上使用贪婪解码和基于分数的预测评估进行评估。
- 与基线如 PaLM-2L 和 GPT-4 比较,结合 CoT、TDB 及 RAG 视情况适用。
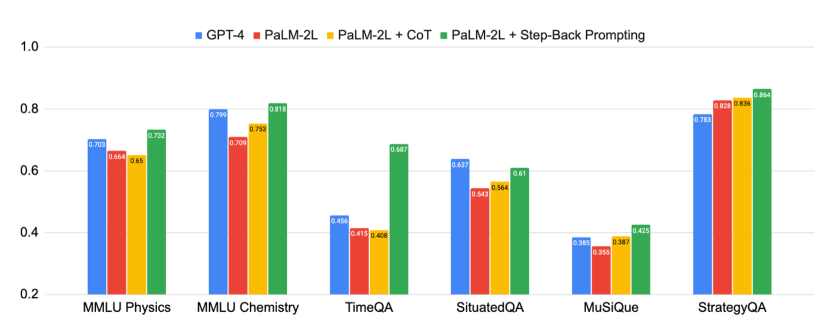
实验结果
研究问题
- RQ1与标准提示和链式推理提示相比,Step-Back Prompting 是否在 STEM、知识问答和多跳任务上提高了准确性?
- RQ2抽象步骤对演示次数的鲁棒性如何?
- RQ3哪些类型的错误最受影响于基于抽象的推理(例如推理、数学或上下文丢失)?
主要发现
- Step-Back Prompting 将 PaLM-2L 在 MMLU Physics 上的表现提升了 7 个百分点,在 MMLU Chemistry 上提升了 11 个百分点,在这两个子任务上都优于 GPT-4。
- Step-Back Prompting 相对于 PaLM-2L 基线在 TimeQA 上提升 27%,在 MuSiQue 上提升 7%。
- 在多项任务中,Step-Back 在某些分析中比 CoT 和 TDB 高出多达 36%,并修正了高达约 40% 的基线模型错误,同时产生的新错误比例较小,约 12%。
- 消融分析显示 Step-Back 对少样本演示次数具有鲁棒性,通常只需一个示例即可教授抽象。
- 错误分析表明,剩余错误大多发生在 Reasoning 步骤,而非 Abstraction 步骤,凸显推理是主要瓶颈。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。