[论文解读] TD-MPC2: Scalable, Robust World Models for Continuous Control
TD-MPC2在鲁棒性与可扩展性方面对TD-MPC进行了扩展,在单一超参数集下对104个连续控制任务表现出强劲性能,并将世界模型扩展到最高317M参数以支持多任务学习。
TD-MPC is a model-based reinforcement learning (RL) algorithm that performs local trajectory optimization in the latent space of a learned implicit (decoder-free) world model. In this work, we present TD-MPC2: a series of improvements upon the TD-MPC algorithm. We demonstrate that TD-MPC2 improves significantly over baselines across 104 online RL tasks spanning 4 diverse task domains, achieving consistently strong results with a single set of hyperparameters. We further show that agent capabilities increase with model and data size, and successfully train a single 317M parameter agent to perform 80 tasks across multiple task domains, embodiments, and action spaces. We conclude with an account of lessons, opportunities, and risks associated with large TD-MPC2 agents. Explore videos, models, data, code, and more at https://tdmpc2.com
研究动机与目标
- 推动鲁棒、通用的基于模型的强化学习,能够利用大型、未筛选的多任务数据集。
- 开发可扩展的世界模型架构,在不同实现和动作空间下工作且无需针对任务的微调。
- 证明在多任务环境中,模型和数据越大能力越好。
- 提供开源资源(模型、数据、代码),以促进更广泛的采用与可重复性。
提出的方法
- 学习一个隐式的、无解码器的世界模型,在给定动作序列的条件下预测结果。
- 使用联合嵌入预测、奖励预测和TD学习来训练世界模型,而不对观测进行解码。
- 对奖励和价值目标采用对数变换空间中的离散回归(交叉熵)形式,以稳定训练。
- 训练一个Q函数的集合,并使用EMA目标以降低TD目标的偏差。
- 使用模型预测控制(MPC)进行规划,结合带策略先验的MPPI来引导搜索,并以学习得到的终端价值进行引导。
- 在多任务设置中,学习一个固定维度、归一化的任务嵌入来对所有组件进行条件化,并使用动作掩码来处理可观测/动作空间的变量。
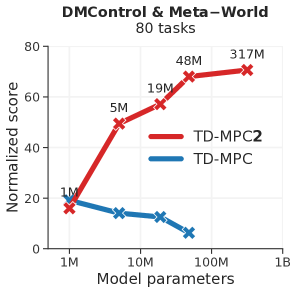
实验结果
研究问题
- RQ1TD-MPC2与数据效率型连续控制任务的最新无模型方法和基于模型的方法相比如何?
- RQ2在单一超参数集下,算法创新是否能够在广泛任务上提供鲁棒的性能?
- RQ3在大规模多任务的TD-MPC2代理中,模型和数据越大能力越强吗,单个代理是否可以跨领域执行多任务?
- RQ4设计选择(归一化、回归目标、Q函数数量)对性能有何影响,规划的重要性有多大?
- RQ5学习得到的任务嵌入是否具有语义意义,大型多任务代理能否适应未见任务?
主要发现
- TD-MPC2在104个任务上以单一超参数集超越了强基线方法(SAC、DreamerV3、原始TD-MPC)。
- 模型和数据规模的增加提升代理能力,317M参数的世界模型实现跨域的80个任务。
- 多任务TD-MPC2模型显示任务嵌入按动力学/对象交互聚类,且更大模型在没有清晰饱和的情况下持续提升。
- TD-MPC2在此前方法易发散的挑战性任务中保持稳定,规划对性能贡献显著。
- 训练成本随模型规模上升,例如317M参数模型在约33个GPU日的训练后,在80任务数据集上实现归一化分数约70.6。
- TD-MPC2支持对保留任务进行少-shot微调,在低数据场景下相较从零开始提升约2倍。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。