[论文解读] TDN: Temporal Difference Networks for Efficient Action Recognition
该论文提出Temporal Difference Networks (TDN),一种轻量级、高效的视频动作识别框架,通过时间差分模块(TDM)捕捉多尺度运动模式。通过在局部(连续帧)和全局(片段级)尺度上应用时间差分,TDN在计算开销极低的情况下提升了动作识别的准确率,在Something-Something V1/V2上达到新的SOTA结果,在Kinetics-400上也表现出具有竞争力的性能。
Temporal modeling still remains challenging for action recognition in videos. To mitigate this issue, this paper presents a new video architecture, termed as Temporal Difference Network (TDN), with a focus on capturing multi-scale temporal information for efficient action recognition. The core of our TDN is to devise an efficient temporal module (TDM) by explicitly leveraging a temporal difference operator, and systematically assess its effect on short-term and long-term motion modeling. To fully capture temporal information over the entire video, our TDN is established with a two-level difference modeling paradigm. Specifically, for local motion modeling, temporal difference over consecutive frames is used to supply 2D CNNs with finer motion pattern, while for global motion modeling, temporal difference across segments is incorporated to capture long-range structure for motion feature excitation. TDN provides a simple and principled temporal modeling framework and could be instantiated with the existing CNNs at a small extra computational cost. Our TDN presents a new state of the art on the Something-Something V1 & V2 datasets and is on par with the best performance on the Kinetics-400 dataset. In addition, we conduct in-depth ablation studies and plot the visualization results of our TDN, hopefully providing insightful analysis on temporal difference modeling. We release the code at https://github.com/MCG-NJU/TDN.
研究动机与目标
- 解决视频动作识别中高效且有效的时序建模挑战。
- 设计一种统一的、端到端可训练的框架,通过时间差分联合捕捉外观与运动信息,避免依赖光流或昂贵的3D卷积。
- 通过两级差分建模范式,系统性地研究短期与长期运动建模。
- 通过将轻量级时间差分模块集成到标准2D CNN中,实现在极低计算成本下获得高准确率。
- 通过消融研究与可视化分析,深入理解基于时间差分的运动建模机制。
提出的方法
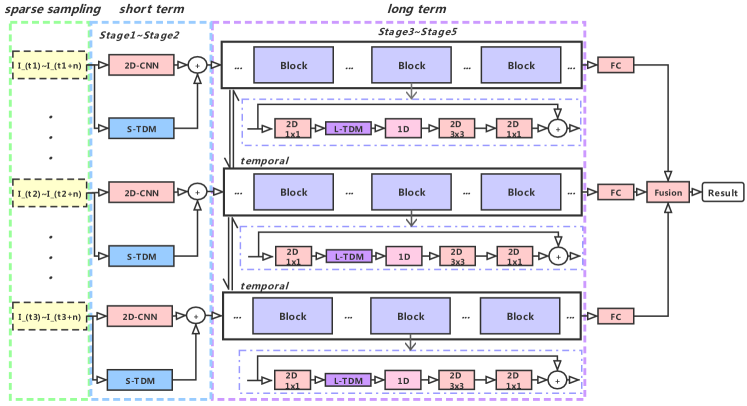
- 提出时间差分模块(TDM),通过计算连续帧之间的差异,提取细粒度运动模式,用于短期建模。
- 在视频片段间采用多尺度、双向差分模块,捕捉长程时间结构,实现全局运动激励。
- 采用两级差分建模策略:局部差分用于帧级运动建模,全局差分用于片段级运动建模。
- 通过侧向连接将时间差分特征注入2D CNN中,实现端到端训练,且参数增加极少。
- 采用整体采样与稀疏采样相结合的方式,高效提取视频中的时间信息。
- 利用Grad-CAM进行可视化,分析并验证TDM的注意力机制。
![Figure 1: Video classification performance comparison on Something-Something V1 [ 8 ] in terms of Top1 accuracy, computational cost, and model size. Our proposed TDN achieves the best trade-off between accuracy and efficiency, when compared with previous methods such as NL I3D [ 40 ] , ECO [ 46 ] ,](https://ar5iv.labs.arxiv.org/html/2012.10071/assets/x1.png)
实验结果
研究问题
- RQ1时间差分操作能否有效替代光流或3D卷积用于视频识别中的运动建模?
- RQ2局部与全局时间差分建模对动作识别性能的影响如何?
- RQ3两级差分建模框架在捕捉多尺度运动模式中的贡献是什么?
- RQ4TDM如何影响特征激活图与模型可解释性?
- RQ5与现有SOTA方法相比,TDN的计算效率如何?
主要发现
- TDN在UCF101上达到97.4%的Top-1准确率,在HMDB51上达到76.3%,优于TSM、I3D和S3D等先前方法,创下新SOTA。
- 在Something-Something V1数据集上,TDN实现了准确率与效率的最佳平衡,优于NL I3D、ECO和TSM等方法。
- 在Tesla V100上,模型每视频推理耗时22.1毫秒(约45.2 FPS),尽管延迟高于部分基线,但仍实现真正的实时推理。
- 消融研究证实,时间差分操作显著提升性能,S-TDM与L-TDM分别在局部与全局运动建模中发挥关键作用。
- 通过Grad-CAM的可视化显示,TDN结合TDM后更关注与运动相关的区域,表明其特征学习能力得到增强。
- 该方法泛化能力出色,能有效从Kinetics-400迁移到较小数据集如UCF101和HMDB51,在动作密集的HMDB51上取得显著性能提升。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。