[论文解读] Temporal Perceiving Video-Language Pre-training
TemPVL 引入一种文本-视频定位预训练任务,将短视频流与文本流合并为长序列,以在没有时序标注的情况下学习细粒度、时序感知的跨模态对齐,从而提升多种视频-语言任务。
Video-Language Pre-training models have recently significantly improved various multi-modal downstream tasks. Previous dominant works mainly adopt contrastive learning to achieve global feature alignment across modalities. However, the local associations between videos and texts are not modeled, restricting the pre-training models' generality, especially for tasks requiring the temporal video boundary for certain query texts. This work introduces a novel text-video localization pre-text task to enable fine-grained temporal and semantic alignment such that the trained model can accurately perceive temporal boundaries in videos given the text description. Specifically, text-video localization consists of moment retrieval, which predicts start and end boundaries in videos given the text description, and text localization which matches the subset of texts with the video features. To produce temporal boundaries, frame features in several videos are manually merged into a long video sequence that interacts with a text sequence. With the localization task, our method connects the fine-grained frame representations with the word representations and implicitly distinguishes representations of different instances in the single modality. Notably, comprehensive experimental results show that our method significantly improves the state-of-the-art performance on various benchmarks, covering text-to-video retrieval, video question answering, video captioning, temporal action localization and temporal moment retrieval. The code will be released soon.
研究动机与目标
- 促进在视频帧与文本描述之间学习细粒度的时序与语义对齐。
- 开发不需要时序注释来监督定位的预训练任务。
- 通过定位引导的多模态学习提升下游视频-语言任务的泛化能力。
提出的方法
- 对视频和文本使用双编码器,并结合一个多模态编码器来融合特征。
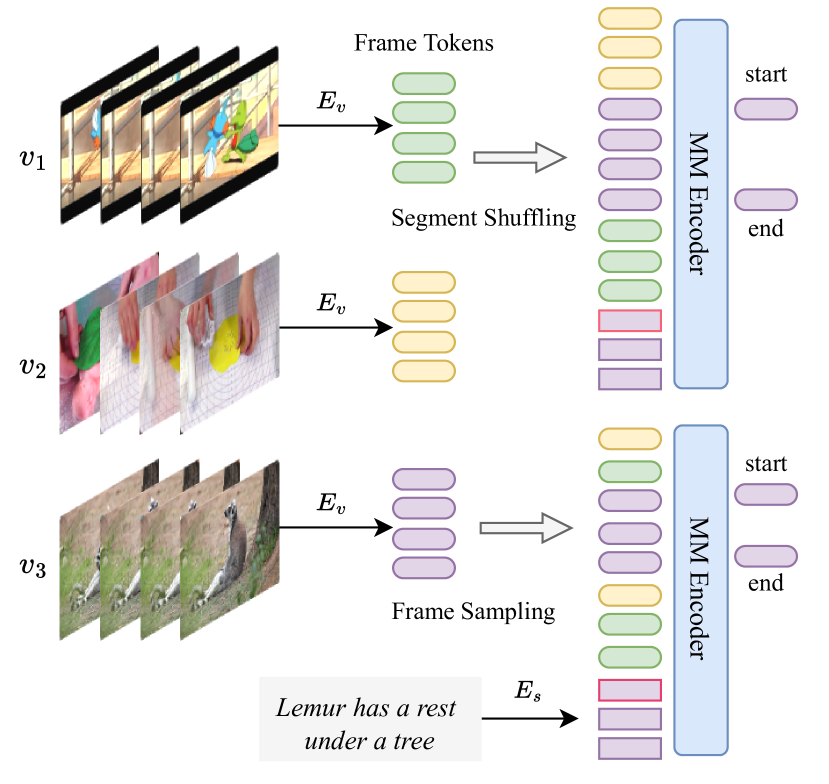
- 通过合并来自多个视频的帧特征来构建长序列,并与合并的文本标记对齐。
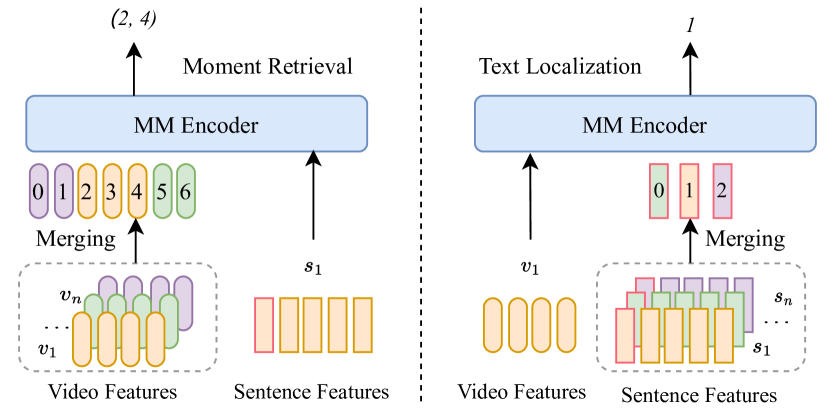
- 引入两种定位目标:与语言的时刻检索和与视频的文本定位。
- 在掩码语言模型和提出的定位损失的基础上,应用文本-视频对比学习目标。
- 使用基于分类的损失预测合并后视频帧的起止边界和合并后文本标记的匹配位置。
实验结果
研究问题
- RQ1基于定位的预训练目标是否能够在无时序标注的情况下提升细粒度的帧到词对齐?
- RQ2将短视频-文本对合并成长序列是否在预训练阶段实现有效的时刻定位和文本定位?
- RQ3文本-视频定位对检索、问答、字幕生成和时序定位等任务的零-shot 与微调性能有何影响?
- RQ4视频和文本序列的合并策略如何影响定位质量及下游任务性能?
主要发现
- TemPVL 提升了 MSR-VTT 和 DiDeMo 的零-shot 文本到视频检索,并在 MSVD 和 LSMDC 上获得提升。
- 该方法在视频问答和视频字幕生成方面相较强基线有改进。
- 从提取的特征和定位引导的预训练中,时序动作定位和时刻检索受益,优于现有方法。
- 对视频合并的难采样和基于 CLS 的文本合并提升了定位准确性与下游任务性能。
- 在 TVL 下使用不同骨干网络(SwinT、ViT)在各任务上显示出一致的提升,表明具有鲁棒的泛化能力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。