[论文解读] Tensor Network Quantum Simulator With Step-Dependent Parallelization
该论文提出了一种基于步长依赖并行化的张量网络量子模拟器,实现了迄今为止最大规模的QAOA电路模拟——在Theta超级计算机的1,024个节点上完成了210量子比特、1,785个门的模拟。该方法采用一种新颖的基于步长依赖变量选择的切片算法,有效降低了收缩宽度和内存占用,在保持多轮模拟高效率的同时,相较于非并行化方法实现了最高达512倍的加速。
In this work, we present a new large-scale quantum circuit simulator. It is based on the tensor network contraction technique to represent quantum circuits. We propose a novel parallelization algorithm based on \stepslice . In this paper, we push the requirement on the size of a quantum computer that will be needed to demonstrate the advantage of quantum computation with Quantum Approximate Optimization Algorithm (QAOA). We computed 210 qubit QAOA circuits with 1,785 gates on 1,024 nodes of the the Cray XC 40 supercomputer Theta. To the best of our knowledge, this constitutes the largest QAOA quantum circuit simulations reported to this date.
研究动机与目标
- 推动大规模量子电路经典模拟的极限,特别是QAOA,以界定量子优越性的阈值。
- 解决使用张量网络收缩模拟深色量子电路时面临的高内存与计算成本问题。
- 开发一种可扩展、高性能的并行化策略,以降低张量网络模拟中的收缩宽度和内存使用。
- 实现对多个QAOA参数变体的收缩顺序高效复用,以支持优化与分析。
提出的方法
- 模拟器将量子电路表示为张量网络,并使用桶消除算法生成收缩顺序。
- 提出一种新颖的步长依赖切片算法,根据当前收缩步骤动态选择切片变量,以降低最大收缩宽度。
- 通过预先收缩部分张量表达式,将张量表达式拆分为更小的片段,从而减少重复计算收缩顺序的需求。
- 该算法在分布式系统(Theta超级计算机)上实现,最多使用1,024个节点和213 TB内存。
- 通过复用相同的收缩顺序,实现了对多个振幅的高效模拟,开销极小。
- 切片策略经过优化,以最小化各步骤中的最大收缩宽度,性能在不同并行索引数量下进行了评估。
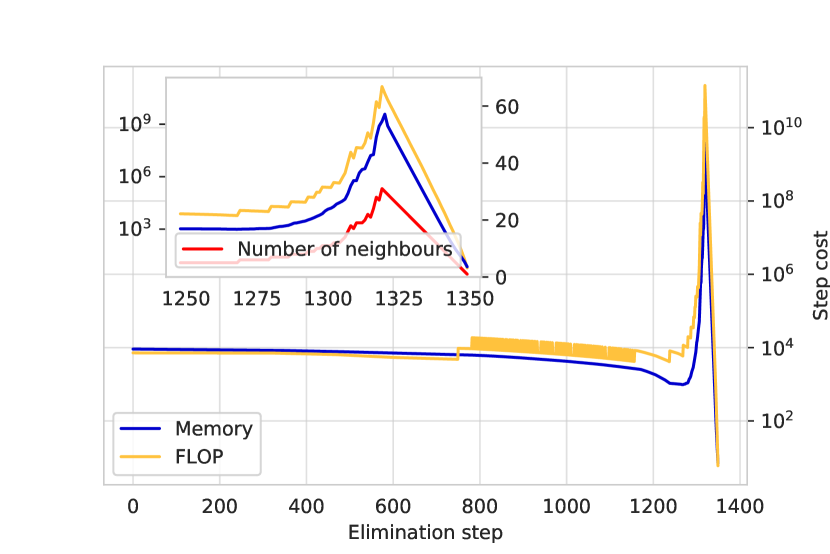
实验结果
研究问题
- RQ1步长依赖切片是否能显著降低大规模张量网络模拟中的收缩宽度和内存占用?
- RQ2在采用先进并行化的张量网络收缩下,QAOA电路的最大可实现量子比特数是多少?
- RQ3与标准并行化方法相比,步长依赖切片在加速比和内存效率方面的表现如何?
- RQ4在不同QAOA参数集之间,单个收缩顺序能在多大程度上被复用以加速模拟?
- RQ5增加并行索引数量对最小收缩宽度和整体模拟时间有何影响?
主要发现
- 该模拟器成功实现了210量子比特QAOA变分电路态的模拟,包含1,785个门,创下迄今最大规模QAOA电路模拟的新纪录。
- 在Theta超级计算机的1,024个节点上运行,相比64个节点的执行,时间减少了3倍,收缩宽度降低至29。
- 步长依赖切片算法相较于非并行化收缩步骤,实现了最高512倍的加速,超过简单并行化的理论64倍上限。
- 该方法将累计内存使用量降低至64个节点上13 TB可用内存的60%,相比串行方法节省了超过35倍内存。
- 每增加一个切片索引,最小收缩宽度即减少1,表明性能提升具有可预测性和可扩展性。
- 该算法支持在不同QAOA参数集之间高效复用收缩顺序,为大规模参数优化和角度可转移性研究提供了支持。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。