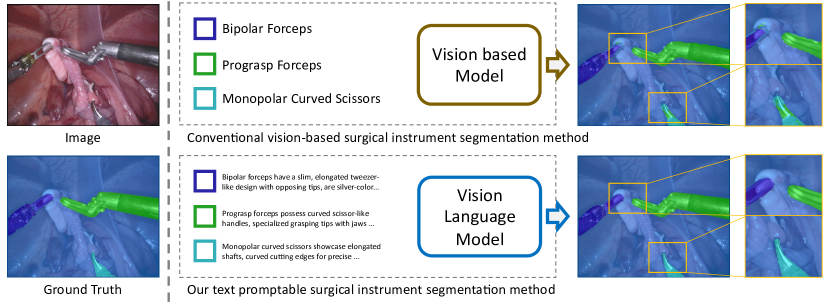
[论文解读] Text Promptable Surgical Instrument Segmentation with Vision-Language Models
引入一个文本可提示的外科器械分割框架,使用基于 CLIP 的图像和文本编码器,以及文本提示的掩码解码器,结合多提示混合机制和一个硬区域强化模块,以提升对各类器械的分割,并实现对新类别的泛化。
In this paper, we propose a novel text promptable surgical instrument segmentation approach to overcome challenges associated with diversity and differentiation of surgical instruments in minimally invasive surgeries. We redefine the task as text promptable, thereby enabling a more nuanced comprehension of surgical instruments and adaptability to new instrument types. Inspired by recent advancements in vision-language models, we leverage pretrained image and text encoders as our model backbone and design a text promptable mask decoder consisting of attention- and convolution-based prompting schemes for surgical instrument segmentation prediction. Our model leverages multiple text prompts for each surgical instrument through a new mixture of prompts mechanism, resulting in enhanced segmentation performance. Additionally, we introduce a hard instrument area reinforcement module to improve image feature comprehension and segmentation precision. Extensive experiments on several surgical instrument segmentation datasets demonstrate our model's superior performance and promising generalization capability. To our knowledge, this is the first implementation of a promptable approach to surgical instrument segmentation, offering significant potential for practical application in the field of robotic-assisted surgery. Code is available at https://github.com/franciszzj/TP-SIS.
研究动机与目标
- 解决在不重新标注和重新训练的情况下,外科器械分割对新颖且多样化的器械类型的泛化能力有限的问题。
- 利用视觉-语言预训练将图像区域与文本器械提示对齐,以实现灵活的开集分割。
- 开发具有注意力与卷积提示的文本提示掩码解码器,逐步细化器械定位。
- 引入混合提示(MoP)机制,将多条文本提示融合以实现对变体的鲁棒分割。
- 通过与 MAE 类重建目标整合的硬器械区域强化模块,提升在硬区域的特征学习。
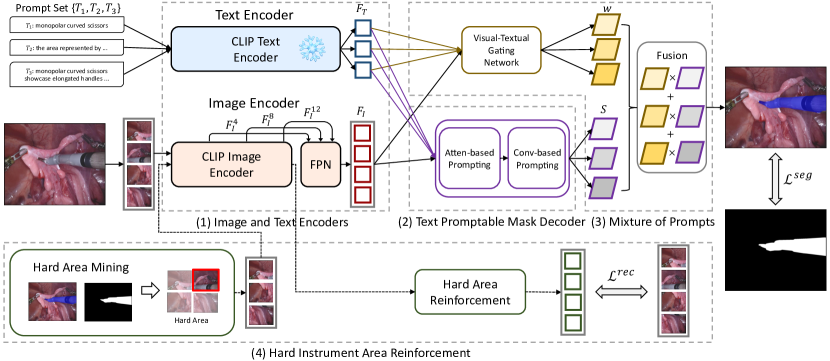
提出的方法
- 以 CLIP 的图像和文本编码器作为骨干,提取内镜图像和器械描述中的视觉与文本特征。
- 实现一个文本提示掩码解码器,包含两种提示方案:基于注意力的提示(自注意力与跨注意力,使用 F_T)和基于卷积的提示(从 F_T 派生的动态卷积核参数)。
- 采用混合提示(MoP),并配合可视觉-文本门控网络,在像素级融合多条提示引导的得分图。
- 引入一个硬区域强化模块,挖掘难以分割的区域并应用 MAE 风格的重建目标,以强化在困难区域的特征学习。
- 使用分割损失(二元交叉熵)和 MAE 基于模块的重建损失(L2)进行训练;冻结文本编码器,微调图像编码器。
实验结果
研究问题
- RQ1一个文本可提示分割框架是否能够在不重新标注或重新训练的情况下对未见过的外科器械类型实现泛化?
- RQ2通过视觉-文本门控网络融合多条文本提示是否能在器械类别间提升分割精度?
- RQ3硬区域强化是否提升在挑战性外科场景中的边缘精度与类别判别能力?
- RQ4多尺度图像特征融合和文本引导如何影响 EndoVis 数据集上的分割性能?
主要发现
- 在 EndoVis2017 和 EndoVis2018 数据集上达到最先进性能,优于传统预定义类别方法及其他文本可提示方法。
- 在 EndoVis2017 上,Ours (896) 获得 Ch_IoU 79.90、ISI_IoU 77.83、mc_IoU 56.22,在多项指标上超越先前方法。
- 在 EndoVis2018 上,Ours (896) 获得 Ch_IoU 84.92、ISI_IoU 83.61、mc_IoU 65.44,显示出强的跨数据集泛化能力。
- 跨数据集(在 EndoVis2018 训练,在 EndoVis2017 测试)获得具有竞争力的结果,证明对开放类别器械的泛化能力。
- 消融研究表明多尺度特征增强、基于 CLS 的文本特征,以及注意力式与卷积式提示的组合显著提升了性能。
- 在 MoP 框架中,GPT-4 生成的提示在各种提示类型中提供了最佳增益。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。