[论文解读] Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
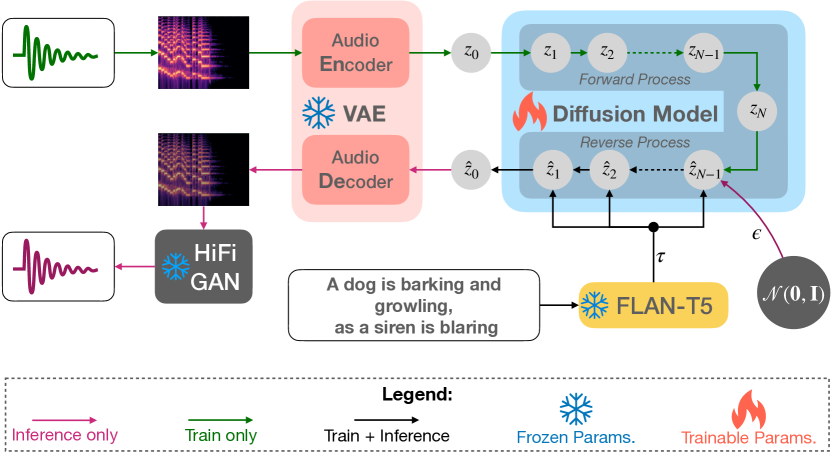
Tango 使用一个被冻结的指令微调的 LLM(Flan-T5)作为文本编码器,并结合潜在扩散模型从文本生成音频,在 AudioCaps 上实现最先进的结果,同时所需训练数据量远小于以往方法。
The immense scale of the recent large language models (LLM) allows many interesting properties, such as, instruction- and chain-of-thought-based fine-tuning, that has significantly improved zero- and few-shot performance in many natural language processing (NLP) tasks. Inspired by such successes, we adopt such an instruction-tuned LLM Flan-T5 as the text encoder for text-to-audio (TTA) generation -- a task where the goal is to generate an audio from its textual description. The prior works on TTA either pre-trained a joint text-audio encoder or used a non-instruction-tuned model, such as, T5. Consequently, our latent diffusion model (LDM)-based approach TANGO outperforms the state-of-the-art AudioLDM on most metrics and stays comparable on the rest on AudioCaps test set, despite training the LDM on a 63 times smaller dataset and keeping the text encoder frozen. This improvement might also be attributed to the adoption of audio pressure level-based sound mixing for training set augmentation, whereas the prior methods take a random mix.
研究动机与目标
- 通过对文本编码器进行极小的微调来激发文本到音频的生成。
- 探索将指令微调的 LLM 作为冻结文本编码器用于 TTA 的有效性。
- 在 AudioCaps 上将 Tango 与前沿基线方法进行对比评估。
- 展示通过数据集规模缩减和有针对性的增强来实现的数据高效训练。
提出的方法
- 使用 Flan-T5-Large 作为冻结文本编码器以获取文本表征。
- 采用潜在扩散模型来生成以文本嵌入为条件的音频先验。
- 训练音频 VAE 和 HiFi-GAN 声码器以从梅尔频谱潜在表征重构波形。
- 使用基于压力级的音频混合来增强训练数据,以更好地保留源声音。
- 应用无分类器引导以通过文本提示引导扩散采样。
- 在显著更小的 AudioCaps 数据集上进行训练(小63倍)同时保持竞争性能。
实验结果
研究问题
- RQ1保持冻结的指令微调 LLM 是否能为基于扩散的音频生成器提供足够的跨模态引导?
- RQ2基于压力级的数据增强是否会改善 TTA 的跨模态概念组合?
- RQ3在 AudioCaps 上训练时,Tango 在客观和主观指标上与 AudioLDM 及其他基线相比如何?
- RQ4推理步数和引导尺度对音质和相关性有何影响?
主要发现
- Tango 在 AudioCaps 上仅凭 AudioCaps 监督和冻结的 Flan-T5 编码器,达到最先进的 FD(24.52)、KL(1.37) 和 FAD(1.59)。
- Tango 获得很高的主观分数(OVL 85.94,REL 80.36),表明音质和文本相关性更优。
- 尽管使用的训练数据集小63倍,Tango 的性能超过 AudioLDM-L,并与若干 AudioLDM-FT 变体基本匹配或优于之。
- 相对基于压力的增强比随机增强在客观指标上更好(FD 24.52 vs 25.84;KL 1.37 vs 1.38;FAD 1.59 vs 2.72)。
- 在 100 步至 200 步之间有显著提升,增加推理步数和适当的无分类器引导(尺度约为 3)可提升 Tango 的性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。