[论文解读] Textbooks Are All You Need
作者使用一个小型高质量数据集混合(CodeTextbook 和 CodeExercises)训练一个具有13亿参数的代码模型 phi-1,并展示了在比以往模型显著更少的数据和计算量下的强代码生成性能,包括 HumanEval 和 MBPP 的 pass@1 分数。
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
研究动机与目标
- 调查高质量、教科书式数据是否能在小规模下显著提升代码语言模型的性能。
- 证明一个 1.3B 参数的 Transformer 在有限的训练数据和计算量下也能达到具有竞争力或最先进的结果。
- 展示针对性的代码练习微调所带来的新兴能力与非局部收益。
- 在评估训练于合成数据集的代码模型时,考察数据整理、过滤及潜在的数据污染问题。
提出的方法
- 在 CodeTextbook 预训练混合(过滤的 The Stack/StackOverflow 代码 + 合成教材),总计约 50B tokens,训练一个 1.3B 参数的解码器式 Transformer(24 层,隐藏维度 2048,32 注意力头),命名为 phi-1。
- 在一个小规模的 CodeExercises 数据集(~180M tokens)上微调 phi-1-base,以获得 phi-1,使用相同的硬件和训练设置,调整超参数。
- 将 phi-1 与更大、成熟的模型在 HumanEval 和 MBPP 上的 pass@1 进行对比,并分析 emergent capabilities 相对于 phi-1-base 和 phi-1-small。
- 结合数据过滤(GPT-4 注解和基于 Transformer 的分类器)来筛选高质量的教育性代码样本,并用 GPT-3.5 合成教材和练习用于预训练和微调。
- 通过非传统的问题集由 GPT-4 评分和数据裁剪实验来评估数据污染问题,以评估性能的鲁棒性。
- 报告架构、训练设置(fp16、AdamW、线性 warmup-decay、8x A100、Deepspeed)以及数据集组成(CodeTextbook、CodeExercises)。
实验结果
研究问题
- RQ1高质量、教科书式数据是否能够在不依赖于海量训练数据和计算资源的情况下显著提升代码生成性能?
- RQ2在小规模、聚焦数据集(CodeExercises)上进行微调对超出微调集合之外的代码任务有何影响( emergent capabilities)?
- RQ3数据整理和合成数据生成策略是否能显著优于标准代码语料库在向 LLM 传授编程概念方面?
- RQ4报告的结果对潜在的数据污染或从训练到评估基准的泄漏有多鲁棒?
- RQ5在 HumanEval 和 MBPP 上,phi-1 与更大基线的比较优劣何在?
主要发现
| Model | Size (Parameters) | Training tokens | HumanEval Pass@1 | MBPP Pass@1 |
|---|---|---|---|---|
| phi-1 | 1.3B | 7B | 50.6% | 55.5% |
| phi-1-base | 1.3B | 7B | 29% | - |
| phi-1-small | 350M | 7B | 45% | - |
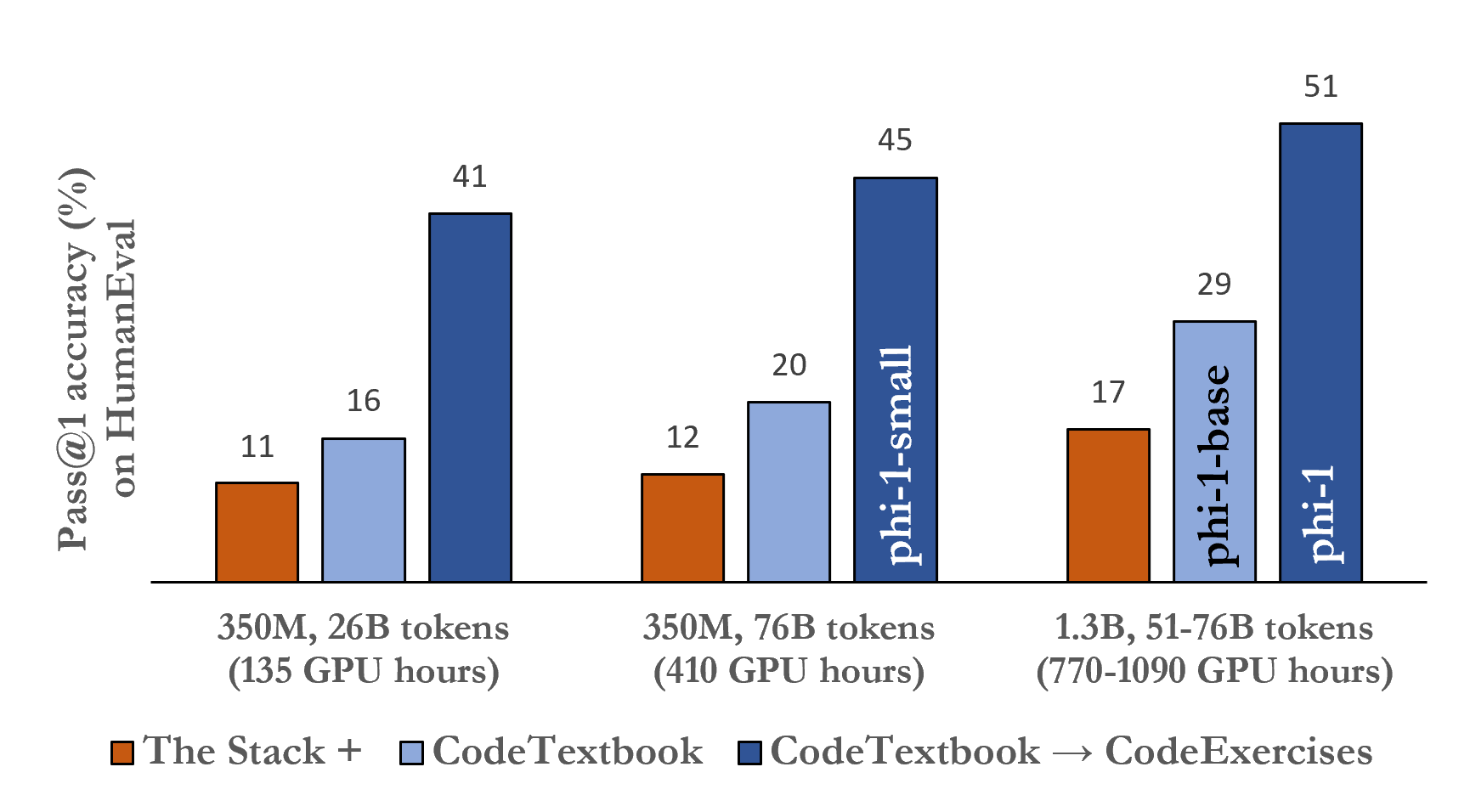
- phi-1(1.3B 参数)在对 CodeExercises 微调后,在 HumanEval 上达到 50.6%、在 MBPP 上达到 55.5%。
- 若不进行微调,在 CodeTextbook 上训练的 phi-1-base 对 HumanEval 达到 29%,而 phi-1-small(350M)在相同流程下约达到 45% 的 HumanEval。
- Phi-1 在 HumanEval 和 MBPP 上超越了许多更大模型,尽管训练数据和计算量少了若干数量级,GPT-4 在某些情况下仍然是上限。
- 在 CodeExercises 上进行微调带来显著的性能提升,并在其他编码任务和库使用(如外部库 Pygame、Tkinter)方面出现意想不到的改进。
- 以数据质量为核心的预训练(CodeTextbook)加上针对性的微调(CodeExercises)能够在小规模下打破传统的扩展规律,取得强结果。
- 使用 GPT-4 评分的非常规评估和数据裁剪实验支持 phi-1 性能的鲁棒性,并缓解对数据污染的担忧。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。