[论文解读] The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
FineWeb 是一个由 96 个 Common Crawl 快照派生的 15 万亿令牌的开放预训练数据集,包含教育子集 FineWeb-Edu,1.3 万亿令牌;作者记录了端到端的整理与消融研究,在开源数据上实现了强劲表现。
The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3 and Mixtral are not publicly available and very little is known about how they were created. In this work, we introduce FineWeb, a 15-trillion token dataset derived from 96 Common Crawl snapshots that produces better-performing LLMs than other open pretraining datasets. To advance the understanding of how best to curate high-quality pretraining datasets, we carefully document and ablate all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies. In addition, we introduce FineWeb-Edu, a 1.3-trillion token collection of educational text filtered from FineWeb. LLMs pretrained on FineWeb-Edu exhibit dramatically better performance on knowledge- and reasoning-intensive benchmarks like MMLU and ARC. Along with our datasets, we publicly release our data curation codebase and all of the models trained during our ablation experiments.
研究动机与目标
- 为公开的高质量预训练数据为开放的大型语言模型提供必要性进行动机说明。
- 开发并发布一个具有透明整理管线的大规模网页文本数据集(FineWeb)。
- 系统性地对筛选、去重和文本提取选择进行消融与文档化,以理解对下游性能的影响。
- 使用合成注释创建一个教育子集(FineWeb-Edu),以筛选出知识与推理密集内容。
- 提供工具(datatrove)和训练模型,以支持可重复性和进一步的研究。
提出的方法
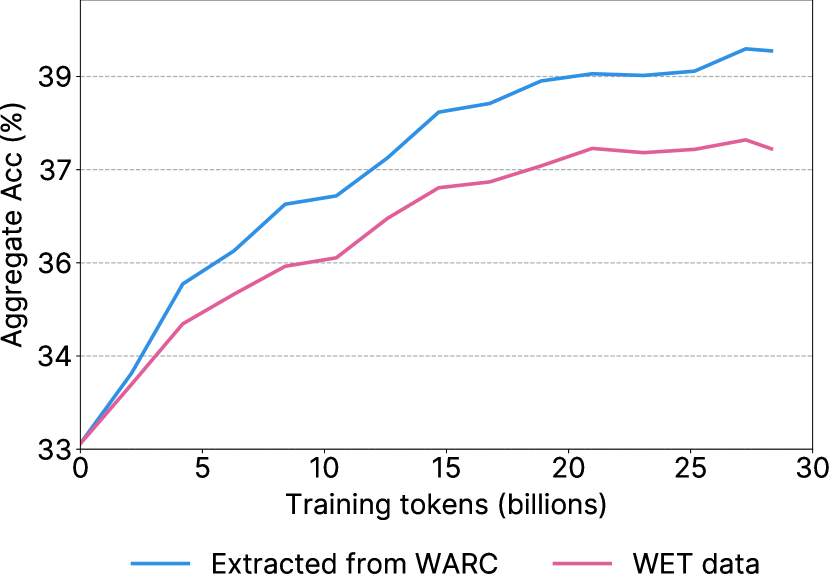
- 使用 Trafilatura 库从 WARC 文件提取文本,以获得比基于 WET 的提取更高质量的文本。
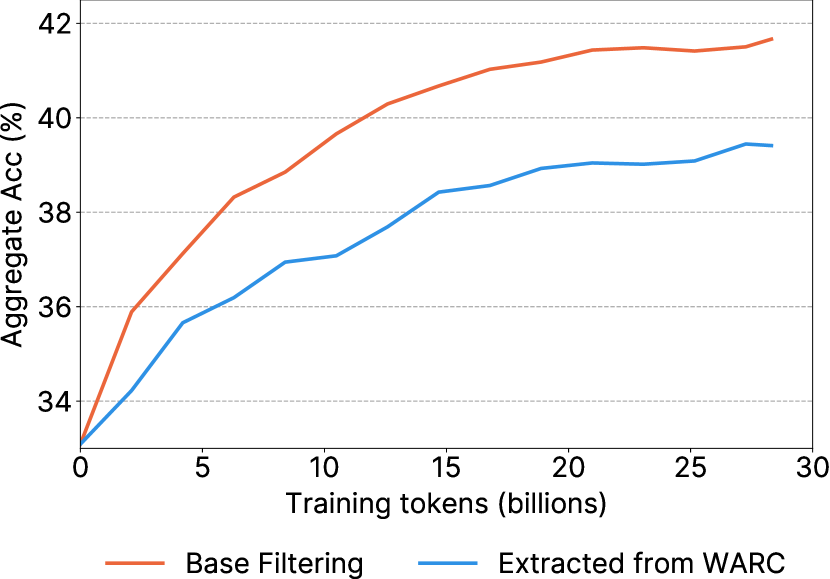
- 应用基础筛选管线,包括 URL 黑名单、fastText 的英文语言筛选,以及受 MassiveText 启发的质量/重复性筛选。
- 对每次抓取执行 MinHash 去重,使用 5-gram 和 112 个哈希函数覆盖14 个桶以减少重复。
- 通过选定的 C4 风格启发式筛选器来增强筛选,提升基准性能而不过度损失令牌。
- 通过分析高/低质量数据分布开发额外的启发式筛选,选取3个筛选器以提升聚合分数。
- 发布数据集、datatrove 处理库和消融模型,以实现可重复性。
实验结果
研究问题
- RQ1文本提取、筛选和去重决策如何影响在开放数据集上的下游大语言模型性能?
- RQ2逐抓取去重和有针对性的筛选是否在提升模型质量方面优于全局去重?
- RQ3结合 C4 风格筛选和自定义启发式方法是否比仅使用基础筛选带来可衡量的提升?
- RQ4专门整理的教育内容子集(FineWeb-Edu)是否在知识与推理密集的基准测试中带来改进?
主要发现
- 基于 WARC 的文本提取使用 Trafilatura 的性能优于基于 WET 的提取。
- 基础筛选对原始数据提供显著的提升。
- 逐抓取的独立 MinHash 去重在平均性能上优于全局去重。
- 全 C4 类型筛选器组合的表现优于最佳单一 C4 筛选器,同时移除的令牌更少。
- 自定义启发式筛选器进一步提升聚合基准分数,且在数据损失较少的情况下甚至胜过仅使用 C4。
- FineWeb-Edu 在像 MMLU 和 ARC 这样的教育性基准上以较少的令牌实现更优异的表现。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。