[论文解读] The Generative AI Paradox: "What It Can Create, It May Not Understand"
本文测试 Generative AI Paradox:生成能力常常超过人类般的理解,在语言与视觉任务中揭示了生成与理解之间的对齐较弱的问题。
The recent wave of generative AI has sparked unprecedented global attention, with both excitement and concern over potentially superhuman levels of artificial intelligence: models now take only seconds to produce outputs that would challenge or exceed the capabilities even of expert humans. At the same time, models still show basic errors in understanding that would not be expected even in non-expert humans. This presents us with an apparent paradox: how do we reconcile seemingly superhuman capabilities with the persistence of errors that few humans would make? In this work, we posit that this tension reflects a divergence in the configuration of intelligence in today's generative models relative to intelligence in humans. Specifically, we propose and test the Generative AI Paradox hypothesis: generative models, having been trained directly to reproduce expert-like outputs, acquire generative capabilities that are not contingent upon -- and can therefore exceed -- their ability to understand those same types of outputs. This contrasts with humans, for whom basic understanding almost always precedes the ability to generate expert-level outputs. We test this hypothesis through controlled experiments analyzing generation vs. understanding in generative models, across both language and image modalities. Our results show that although models can outperform humans in generation, they consistently fall short of human capabilities in measures of understanding, as well as weaker correlation between generation and understanding performance, and more brittleness to adversarial inputs. Our findings support the hypothesis that models' generative capability may not be contingent upon understanding capability, and call for caution in interpreting artificial intelligence by analogy to human intelligence.
研究动机与目标
- 推动并形式化 Generative AI Paradox 假设:与人类相比,生成模型中的生成能力可能超过对理解的能力。
- 设计受控实验,比较语言与视觉模型中的生成与理解。
- 量化在不同任务与模态下,判别(理解)表现与生成之间的关系。
- 评估对抗性输入与任务难度对理解的鲁棒性。
- 讨论对 AI 能力的解读及其超越人类智力的含义。
提出的方法
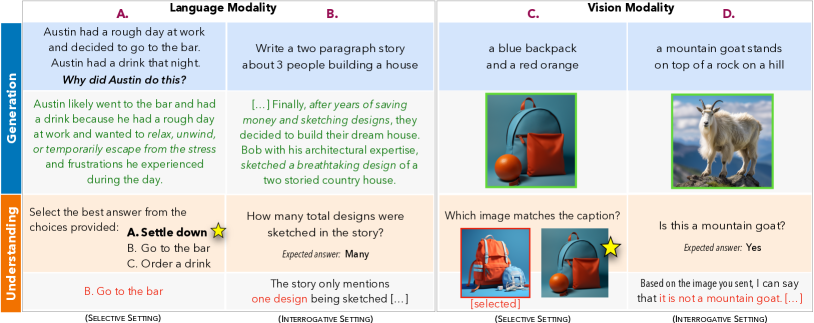
- 将生成定义为为满足输入提示而产生内容;将理解通过选择性(判别)与探问性评估来界定。
- 在语言任务上测试 GPT-3.5、GPT-4,在视觉任务上测试 Midjourney/CLIP/OpenCLIP/BLI P-2、BingChat、Bard,覆盖选择性与探问性设定。
- 使用判别任务(如多选)在评估生成表现的同时衡量理解。
- 在视觉方面,比较生成质量(图像提示)与使用 CLIP/OpenCLIP 的判别任务。
- 通过提示模型回答关于其自身生成内容的问题(语言)或关于生成图像的问题(视觉)来进行探问性评估。
- 引入难的与容易的负候选以在对抗条件下探查判别的鲁棒性。
实验结果
研究问题
- RQ1在同样任务上,最前沿模型的生成表现是否超过人类表现?
- RQ2当生成能力匹配时,模型在判别理解上是否落后于人类?
- RQ3模型是否能够像人类一样高准确率地回答关于自身生成输出的问题(探问性评估)?
- RQ4任务难度与负候选质量如何影响模型的理解与生成?
- RQ5语言与视觉模态之间的差异是否影响生成-理解关系?
主要发现
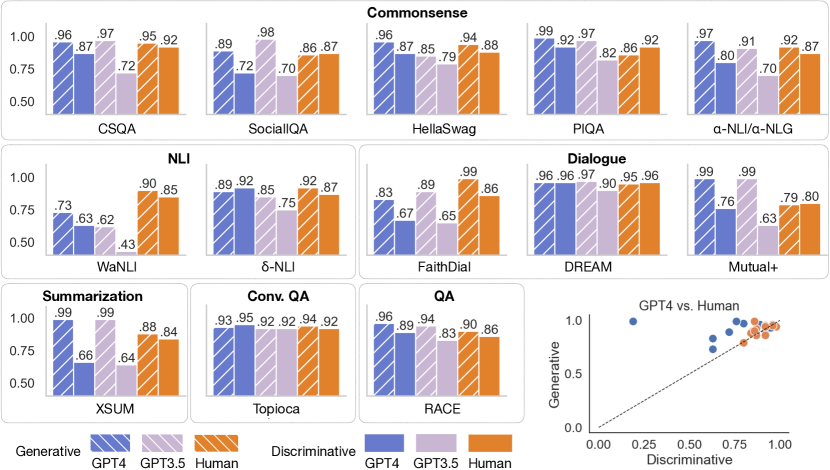
- 在多组数据集中,模型在生成上常常优于人类,但在判别理解上却落后于人类。
- 在人类的理解能力与生成能力之间,判别能力的关联在 GPT-4 上不如在 humans 中紧密。
- 在人类相比的对抗性输入下,人类在判别任务上的鲁棒性高于模型,随着任务难度的增加,模型-人类差距扩大。
- 在探问性评估中,模型在回答关于自身生成内容的问题时常常出错,而人类保持较高准确率。
- 在视觉方面,生成质量高于人类,但在回答关于生成图像的内容相关问题时理解能力落后。
- 在语言方面,13组数据中有10组在至少一个模型(GPT-3.5 或 GPT-4)支持子假设1;在两模型都成立的有7组(GPT-3.5 与 GPT-4)。
- 在视觉方面,CLIP/OpenCLIP 的判别准确率低于人类,但生成质量仍然保持较高水平。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。