[论文解读] The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models
引入 Hallucinations Leaderboard,这是一个开放的平台,在多项任务上评估 LLM 的事实性与忠实性,以在不进行训练的情况下量化幻觉倾向。它分析模型家族、指令微调和规模效应。
Large Language Models (LLMs) have transformed the Natural Language Processing (NLP) landscape with their remarkable ability to understand and generate human-like text. However, these models are prone to ``hallucinations'' -- outputs that do not align with factual reality or the input context. This paper introduces the Hallucinations Leaderboard, an open initiative to quantitatively measure and compare the tendency of each model to produce hallucinations. The leaderboard uses a comprehensive set of benchmarks focusing on different aspects of hallucinations, such as factuality and faithfulness, across various tasks, including question-answering, summarisation, and reading comprehension. Our analysis provides insights into the performance of different models, guiding researchers and practitioners in choosing the most reliable models for their applications.
研究动机与目标
- 量化在多样化任务与设定中,LLM 产生幻觉的频率。
- 将幻觉分为事实性与忠实性两类。
- 评估模型家族、规模与指令微调对幻觉倾向的影响。
提出的方法
- 采用 EleutherAI Evaluation Harness 进行零-shot 和少-shot 评估。
- 定义两种幻觉范围:跨任务的事实性与忠实性。
- 通过两项总体分数(事实性分数和忠实性分数)对任务指标取平均来评估。
- 在多个模型家族与规模上评估开源骨干模型及微调变体。
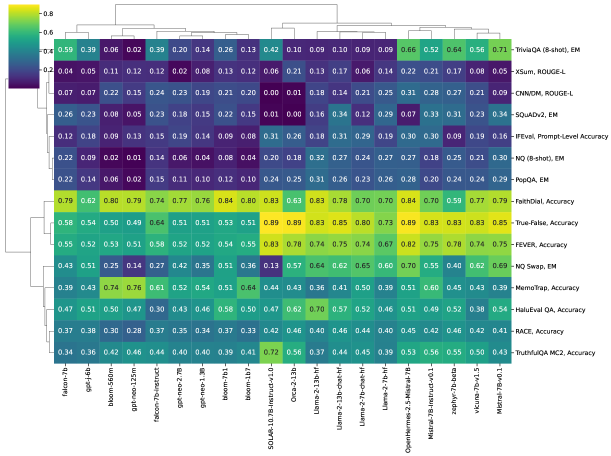
- 使用热力图和分层聚类分析结果,以识别模型与任务之间的模式。
实验结果
研究问题
- RQ1不同 LLM 家族在跨任务的事实性与忠实性方面的比较如何?
- RQ2指令微调对幻觉倾向的影响如何?
- RQ3模型规模如何影响事实性与忠实性?
- RQ4遵循指令与事实正确性之间是否存在权衡?
- RQ5发现是否与关于模型先验与记忆在幻觉中的作用的既有研究一致?
主要发现
- 指令微调的模型通常在忠实性方面有改善,但在事实性方面的提升则呈现混合或有限的效果。
- 事实性往往比忠实性更受模型规模增大所带来的好处。
- 模型聚类往往与模型家族而非单一架构一致,表明共享的训练/数据影响。
- GPT-Neo 与 Llama-2 系列在问答、摘要和检测任务中显示出不同的优势。
- 基于记忆的任务(例如 NQ-open)在表层事实性方面表现较弱,尽管其底层真实表征存在。
- Hallucinations Leaderboard 突出显示了遵循指令(忠实性)与生成事实性正确内容(事实性)之间的现有权衡。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。