[论文解读] The Impact of Positional Encoding on Length Generalization in Transformers
NoPE(无位置编码)在解码器独立 Transformers 的长度泛化方面优于显式位置编码,涵盖推理和数学任务;NoPE 能表示绝对和相对位置,且常表现得像 T5 的 Relative PE。
Length generalization, the ability to generalize from small training context sizes to larger ones, is a critical challenge in the development of Transformer-based language models. Positional encoding (PE) has been identified as a major factor influencing length generalization, but the exact impact of different PE schemes on extrapolation in downstream tasks remains unclear. In this paper, we conduct a systematic empirical study comparing the length generalization performance of decoder-only Transformers with five different position encoding approaches including Absolute Position Embedding (APE), T5's Relative PE, ALiBi, and Rotary, in addition to Transformers without positional encoding (NoPE). Our evaluation encompasses a battery of reasoning and mathematical tasks. Our findings reveal that the most commonly used positional encoding methods, such as ALiBi, Rotary, and APE, are not well suited for length generalization in downstream tasks. More importantly, NoPE outperforms other explicit positional encoding methods while requiring no additional computation. We theoretically demonstrate that NoPE can represent both absolute and relative PEs, but when trained with SGD, it mostly resembles T5's relative PE attention patterns. Finally, we find that scratchpad is not always helpful to solve length generalization and its format highly impacts the model's performance. Overall, our work suggests that explicit position embeddings are not essential for decoder-only Transformers to generalize well to longer sequences.
研究动机与目标
- 研究不同位置编码方案如何影响从头开始训练的解码器独立 Transformer 的长度泛化。
- 比较 Absolute Position Embedding (APE)、T5 的 Relative PE、ALiBi、Rotary 和 NoPE 在一系列推理与数学任务中的表现。
- 评估无位置编码是否可以在下游任务中支持或超过长度泛化。
提出的方法
- 使用从零开始训练、约 1.07 亿参数的传统解码器单 Transformer,采用自回归目标。
- 评估五种位置编码方法:APE(正弦),T5 的 Relative Bias,ALiBi,Rotary,以及 NoPE(无 PE)。
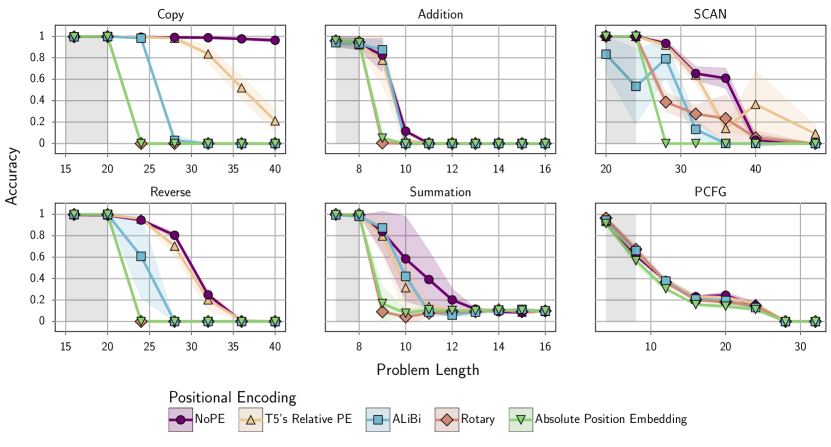
- 在一组综合任务上评估绩效,包括 Primitive(Copy、Reverse)和数学/推理任务(Addition、Polynomial Eval.、Sorting、Summation、Parity、LEGO)以及经典数据集(SCAN、PCFG)。
- 通过在长度上限 L(默认 L=20)进行训练并在长度上限 2L 的数据上评估来测试长度泛化,包括 IISD/扩展长度场景。
- 分析注意力模式和 scratchpad(Chain-of-Thought,CoT)格式,以理解 PE 与长度泛化之间的交互。
- 提供理论结果表明 NoPE 能表示绝对和相对 PEs,并给出实证证据表明 SGD 训练的 NoPE 的行为类似于相对编码,如 T5 的 RPE。
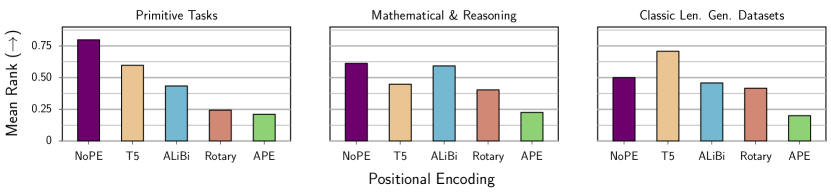
实验结果
研究问题
- RQ1在去除显式位置编码(NoPE)的情况下,解码器独立 Transformer 在多种下游任务上是否能改善长度泛化?
- RQ2在 APE、T5 Relative Bias、ALiBi、Rotary 和 NoPE 中,哪种 PE 方案在更长序列的外推中表现最佳?
- RQ3NoPE 是否可以隐式表示绝对和相对位置,在从零开始训练时它在实践中更像哪一种?
- RQ4scratchpad(CoT)格式如何与不同的 PE 交互影响长度泛化?
- RQ5每种 PE 引发的注意力模式差异是什么,与长度泛化表现有何关系?
主要发现
- NoPE 在跨多个任务的长度泛化上始终优于显式位置编码(APE、ALiBi、Rotary,甚至 T5 的 Relative Bias)。
- NoPE 在不增加注意力计算的情况下实现了与显式 PE 相近或更好的泛化,而显式 PE 需要额外项。
- 理论结果显示 NoPE 能同时表示绝对和相对 PEs,但用 SGD 训练的 NoPE 行为与相对 PE 的注意力模式相一致,类似于 T5 的 RPE。
- Scratchpad 仅在某些任务上对长度泛化有帮助(并非普遍),且取决于其格式和所用的 PE。
- 注意力分析表明 NoPE 和 T5 的 Relative PE 鼓励同时关注长距离和短距离位置,而 ALiBi 偏向于最近的标记,Rotary 在行为上类似于 APE。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。