[论文解读] The Landscape and Challenges of HPC Research and LLMs
本论文综述了大语言模型(LLMs)如何适应高性能计算(HPC),概述了挑战,并讨论了路径、代码表示、多模态方法以及潜在的案例研究。
Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.
研究动机与目标
- 通过突出LLMs和HPC之间潜在的互利关系来推动将LLMs应用于HPC任务。
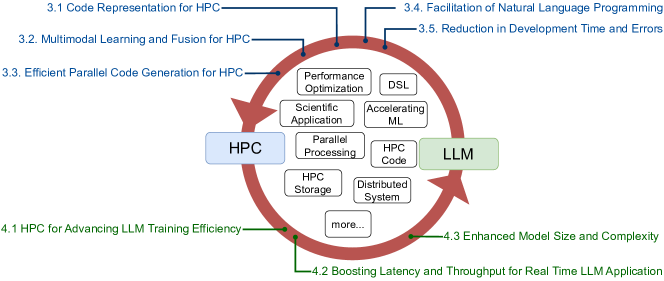
- 识别将LLMs引入HPC领域所特有的挑战,包括数据表示、工具访问和评估指标。
- 提出面向HPC的LLMs的架构和方法方向,包括代码表示、多模态学习和并行代码生成。
- 通过案例研究说明定制化设计如何实现LLMs与HPC之间的互利。
提出的方法
- 回顾在编程和HPC场景下的LLMs相关工作,以发现存在的空白。
- 讨论用于HPC的代码表示,包括源代码文本和LLVM IR,以及它们对LLM任务的影响。
- 探索多模态学习,将代码特征与系统运行时数据融合以进行性能优化。
- 分析LLMs的并行代码生成,并概述数据获取和评估指标等挑战。
- 描述面向HPC的自然语言编程中的NL到PL和PL到NL方面。
- 总结最先进的面向HPC的代码LLMs,以及领域聚焦如何降低训练需求。
实验结果
研究问题
- RQ1将LLMs应用于HPC任务的核心机会是什么?HPC与LLM研究能带来哪些互利?
- RQ2为有效利用LLMs,HPC需要解决哪些独特挑战(数据表示、工具、评估等)?
- RQ3代码表示(如LLVM IR)和多模态融合如何提升LLMs在HPC中的有效性?
- RQ4定制用于HPC的代码LLMs的当前状态如何?并行代码生成与优化任务还存在哪些空白?
主要发现
- LLMs有助于HPC任务,例如并行代码生成,但在跨并行配置的鲁棒性和正确性方面存在挑战。
- 像LLVM IR这样的代码表示可以暴露对HPC重要的语义特征,在某些任务中有时优于原始源文本表示。
- 将代码特征与性能计数器和系统信息相结合的多模态方法可能增强HPC优化任务。
- 面向HPC的最先进LLMs(如代码LLM和HPC定制模型)显示出前景,但仍受限于数据可用性和并行代码评估指标。
- 提出了面向HPC的NL到PL和PL到NL范式,强调在两个方向上利用HPC特定知识以提升可用性和理解。
- 未来的一个流程将HPC资源整合到LLM训练和数据预处理中,可能提高效率和可扩展性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。