[论文解读] The Semantic Scholar Open Data Platform
本论文描述了 Semantic Scholar Open Data Platform 与 Semantic Scholar Academic Graph (S2AG),并概述数据管道、语义特征,以及公共 API/数据集。
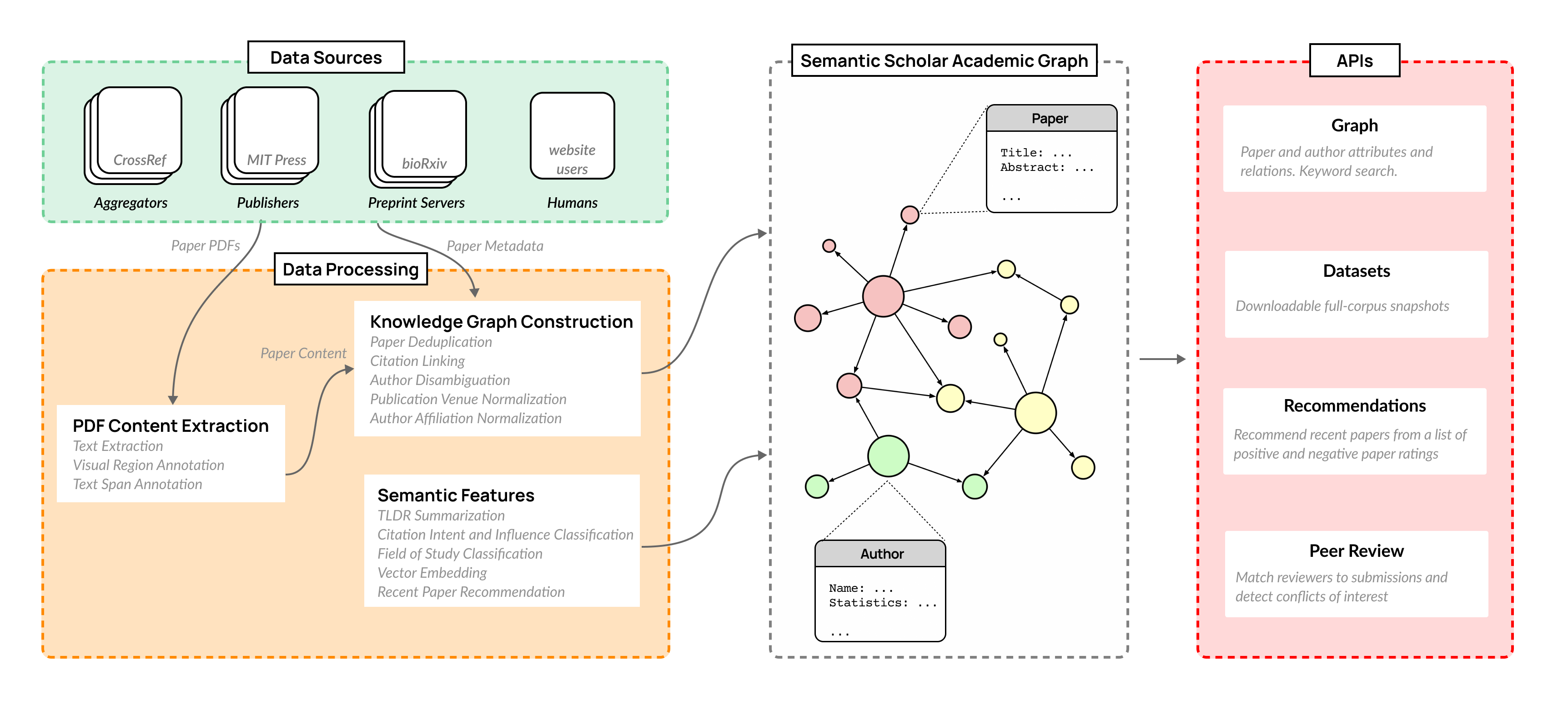
The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
研究动机与目标
- 推动需要自动化学术数据工具以应对信息超载的需求。
- 描述 Semantic Scholar Open Data Platform 与 S2 Academic Graph (S2AG) 作为一个大型、去歧义的知识图谱。
- 解释数据处理管道、数据来源以及提取与构建学术内容的方法。
- Detail the public APIs and downloadable datasets that provide access to S2AG and semantic features.
- Outline future directions to enhance semantic labeling, personalization, and collaboration-driven annotations.
提出的方法
- 从 50+ 来源获取元数据和 PDF 以构建一个去歧义的知识图谱 (S2AG)。
- 执行 PDF 内容提取以获得结构化文本、章节、图形、表格和参考文献。
- 使用视觉区域标注和文本片段标注以用布局和语义标签丰富提取的内容。
- 应用去重(S2APLER)、作者去重(S2AND)和机构归一化(S2AFF)来构建唯一实体。
- 生成语义特征包括 TLDR 摘要、引用意图/影响、研究领域分类、论文嵌入(SPECTER)和推荐。
- 提供 API 和每月数据集快照(论文、作者、引用、嵌入、TLDR、会议/期刊、S2ORC)以供程序访问。
实验结果
研究问题
- RQ1如何从多样化数据源构建一个大规模、开放且去歧义的学术图谱(S2AG)?
- RQ2可以添加哪些语义特征(摘要、嵌入、分类)来增强对科学文献的发现与理解?
- RQ3研究者如何通过 API 和数据集以编程方式访问和下载全面的学术数据与语义注释?
- RQ4需要哪些组件和管道以让知识图谱随持续的出版物和更正保持最新?
主要发现
- S2AG 近似于一个大规模学术图谱,包含 205M 论文、80M 作者、550k 机构、580M 论文-作者边、2.4B 引用边(按所描述的管线)。
- 该平台提供先进的语义特征,如结构化解析文本、TLDR 摘要、向量嵌入(SPECTER)和推荐。
- 该管线整合了 50 多个数据源、复杂的 PDF 内容提取(Text Extraction、Visual Region Annotation、Text Span Annotation)以及多种归一化/去重模型(S2APLER、S2AND、S2AFF)。
- 公开的 API 和每月数据集提供对核心元数据、摘要、全文(在许可范围内)、引用、嵌入和 TLDR 的访问。
- 该系统提供多种用于语义处理的模型和数据集,包括 TLDR(CatTS)、SciCite 用于引用意图、S2FOS 用于研究领域、SPECTER 嵌入以及动态推荐。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。