[论文解读] The What, Why, and How of Context Length Extension Techniques in Large Language Models -- A Detailed Survey
对LLM上下文长度扩展技术的全面综述,分类插值与外推方法,并评审位置编码、内存、检索与微调方法,以及评估挑战。
The advent of Large Language Models (LLMs) represents a notable breakthrough in Natural Language Processing (NLP), contributing to substantial progress in both text comprehension and generation. However, amidst these advancements, it is noteworthy that LLMs often face a limitation in terms of context length extrapolation. Understanding and extending the context length for LLMs is crucial in enhancing their performance across various NLP applications. In this survey paper, we delve into the multifaceted aspects of exploring why it is essential, and the potential transformations that superior techniques could bring to NLP applications. We study the inherent challenges associated with extending context length and present an organized overview of the existing strategies employed by researchers. Additionally, we discuss the intricacies of evaluating context extension techniques and highlight the open challenges that researchers face in this domain. Furthermore, we explore whether there is a consensus within the research community regarding evaluation standards and identify areas where further agreement is needed. This comprehensive survey aims to serve as a valuable resource for researchers, guiding them through the nuances of context length extension techniques and fostering discussions on future advancements in this evolving field.
研究动机与目标
- 在NLP任务中阐明扩展上下文长度对LLM的重要性。
- 提供上下文长度扩展技术的有序分类(插值与外推)。
- 综述现有机制(位置编码、内存/检索、注意力修改)及其零-shot 和微调变体。
- 讨论评估标准、挑战及上下文长度扩展研究中的共识缺口。
- 强调未来工作在扩展上下文长度方面的开放挑战与方向。
提出的方法
- 提出一种将插值和外推技术区分的分类法,包含零-shot 分支和微调分支。
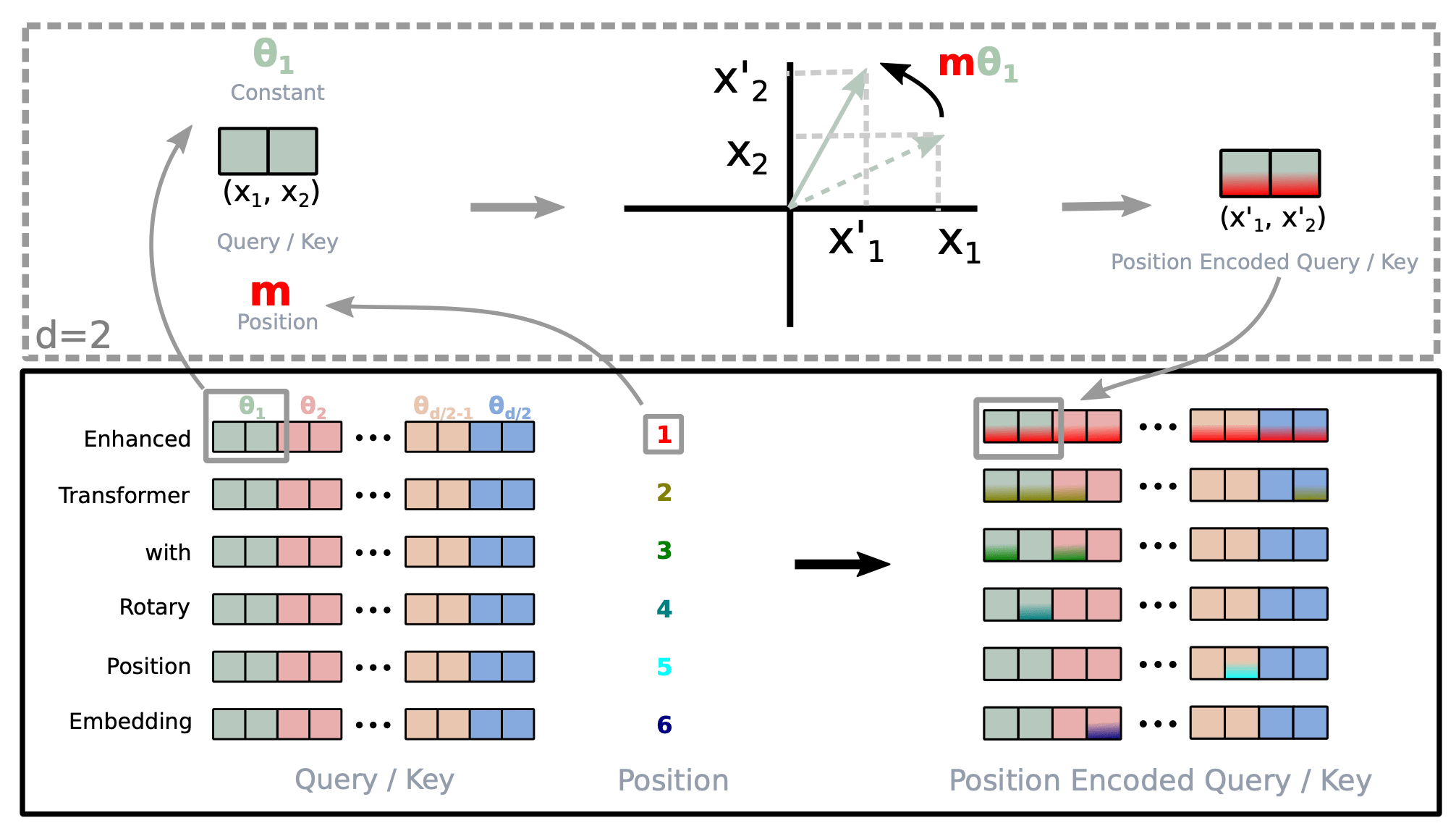
- 评述位置编码方法(RoPE、ALiBi 等)及其外推特性。
- 综述用于长上下文的专用注意力、窗口化以及内存/检索方法。
- 考察诸如 PI、NTK 相关方法以及记忆启发技术(如 Landmark Attention、TiM)等的插值方法。
- 概述零-shot 与微调策略及其在长上下文任务中的适用性。

实验结果
研究问题
- RQ1在LLM中用于扩展上下文长度的主要技术有哪些?
- RQ2插值和外推方法在方法和适用性上有何区别?
- RQ3位置编码、专用注意力和基于内存的方法在长上下文中的优点和局限性是什么?
- RQ4在评估上下文长度扩展技术时存在哪些挑战,是否存在标准共识?
主要发现
- 存在多种长上下文策略,其中基于 RoPE 的、ALiBi 和 PI 是突出的零-shot 外推技术。
- RoPE 及其变体实现相对位置信息,并在长序列中提升外推能力。
- 内存/检索方法和地标标记可以降低计算量,并在训练或推理阶段实现更长的上下文。
- 插值和 NTK 相关方法可以在不同数据需求下使预训练模型适应更长的上下文。
- 在某些外推技术中观察到效率提升和稳定性改善,尽管在准确性和资源使用方面仍存在权衡。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。