[论文解读] Titans: Learning to Memorize at Test Time
Titans 引入了一个深度神经网络的长期记忆模块,该模块在测试时学习记忆,并将其与基于注意力的核心架构整合,以处理极长的上下文,在多样化任务上超过 Transformers 和线性递归模型。
Over more than a decade there has been an extensive research effort on how to effectively utilize recurrent models and attention. While recurrent models aim to compress the data into a fixed-size memory (called hidden state), attention allows attending to the entire context window, capturing the direct dependencies of all tokens. This more accurate modeling of dependencies, however, comes with a quadratic cost, limiting the model to a fixed-length context. We present a new neural long-term memory module that learns to memorize historical context and helps attention to attend to the current context while utilizing long past information. We show that this neural memory has the advantage of fast parallelizable training while maintaining a fast inference. From a memory perspective, we argue that attention due to its limited context but accurate dependency modeling performs as a short-term memory, while neural memory due to its ability to memorize the data, acts as a long-term, more persistent, memory. Based on these two modules, we introduce a new family of architectures, called Titans, and present three variants to address how one can effectively incorporate memory into this architecture. Our experimental results on language modeling, common-sense reasoning, genomics, and time series tasks show that Titans are more effective than Transformers and recent modern linear recurrent models. They further can effectively scale to larger than 2M context window size with higher accuracy in needle-in-haystack tasks compared to baselines.
研究动机与目标
- 设计结合短期注意力与长期记忆的记忆系统以提升记忆能力的动机。
- 提出一个基于惊讶驱动机制在测试时更新的神经长期记忆。
- 展示如何以快速、并行化的方式训练与从长期记忆中检索信息。
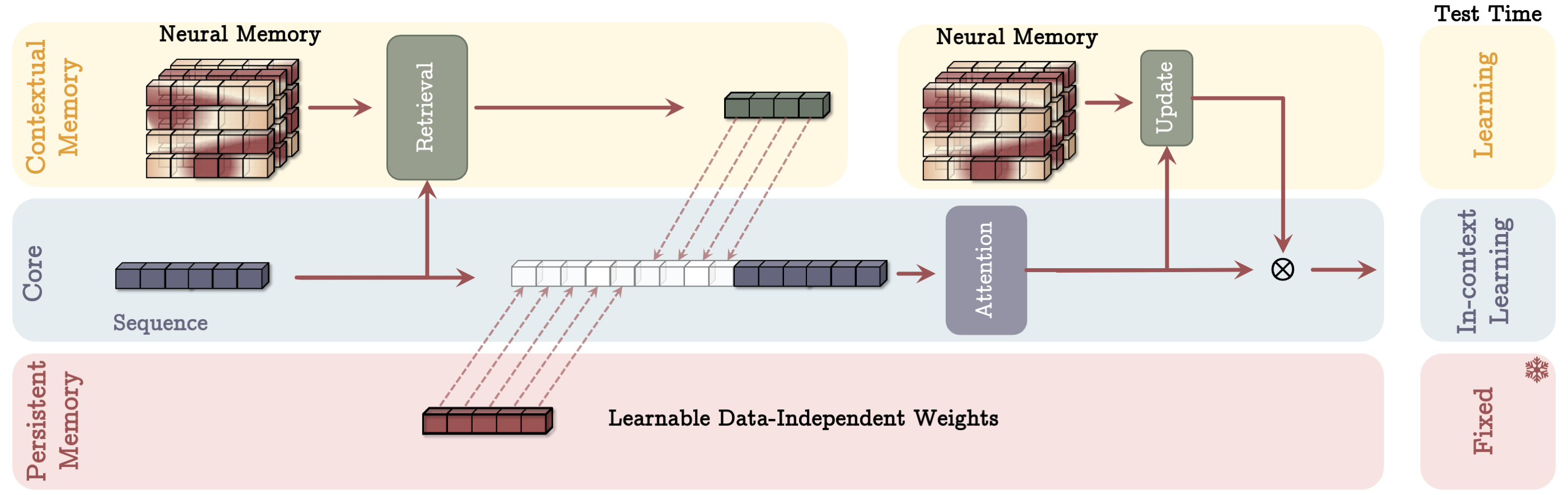
- 将长期记忆与三分支的 Titans 架构(核心、长期记忆、持久记忆)整合。
- 展示在多样化任务中对超过 2 百万标记上下文窗口的可扩展性。
提出的方法
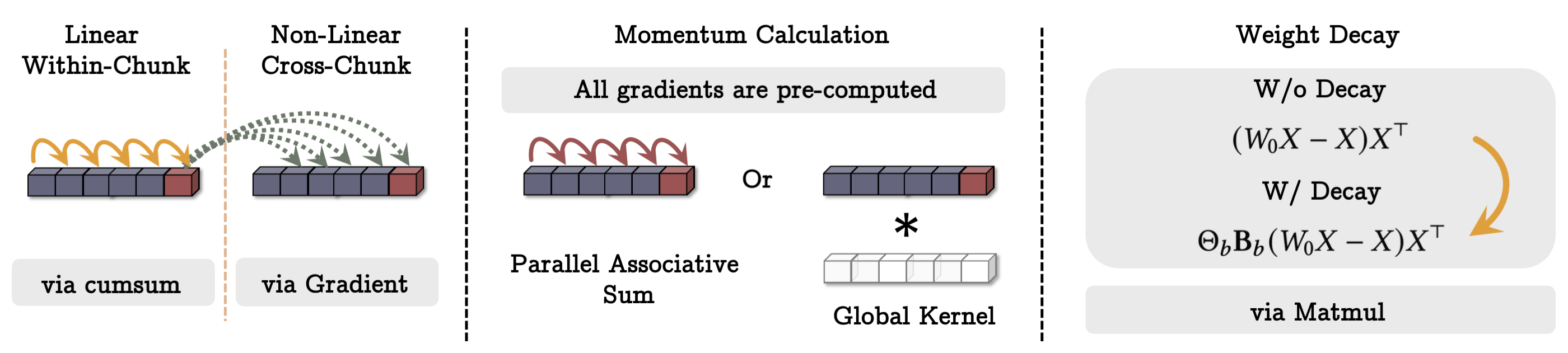
- 引入一个神经长期记忆模块,通过惊讶驱动的更新将过去信息存储到其参数中。
- 用损失相对于输入的梯度定义惊讶,并用数据相关衰减将其分解为过去的惊讶与瞬时惊讶。
- 使用元学习风格的内部循环,通过键–值对上的联想记忆损失来训练记忆。
- 提出一种快速的张量化训练方案,使用小批量梯度下降和基于矩阵乘法的计算以实现并行性。
- 引入一个持久记忆(与任务相关、数据无关),并提出三种 Titans 变体:将记忆用作上下文、用作一层、或作为门控分支。
实验结果
研究问题
- RQ1构成长时依赖关系的有效记忆结构应具备哪些特征?
- RQ2哪种记忆更新机制最适合在长序列中支持记忆与遗忘?
- RQ3检索过程如何高效提取当前任务所需的相关存储信息?
- RQ4如何在不牺牲训练/推理速度的前提下,将内存模块高效整合到架构中?
- RQ5是否需要深度神经长期记忆以实现对鲁棒长远记忆的支持?
主要发现
- Titans 在语言建模、推理、基因组学和时间序列任务上优于现代循环模型及其混合形式。
- 在上下文窗口超过 2M 标记的情况下,Titans 的准确性在 needle-in-haystack 任务上高于基线。
- 长期记忆模块采用惊讶驱动更新和遗忘机制,提升了记忆管理和泛化能力。
- 通过张量化的小批量更新实现并行化训练,使深度记忆的训练更加高效。
- 持久记忆为与输入无关的任务知识提供稳定学习与检索的支撑。
- 三种 Titans 变体(将记忆作为上下文、记忆作为门、以及基于门控的设计)在效率与效果之间提供权衡。)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。