[论文解读] Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs
该论文表明数字分词方向(从左到右 L2R 与从右到左 R2L)显著影响 GPT-3.5 和 GPT-4 的算术性能,R2L 通常能得到更好结果;模型可以通过转换分词来恢复性能,且这一效应在更大模型中仍然存在。
Tokenization, the division of input text into input tokens, is an often overlooked aspect of the large language model (LLM) pipeline and could be the source of useful or harmful inductive biases. Historically, LLMs have relied on byte pair encoding, without care to specific input domains. With the increased use of LLMs for reasoning, various number-specific tokenization schemes have been adopted, with popular models like LLaMa and PaLM opting for single-digit tokenization while GPT-3.5 and GPT-4 have separate tokens for each 1-, 2-, and 3-digit numbers. In this work, we study the effect this choice has on numerical reasoning through the use of arithmetic tasks. We consider left-to-right and right-to-left tokenization for GPT-3.5 and -4, finding that right-to-left tokenization (enforced by comma separating numbers at inference time) leads to largely improved performance. Furthermore, we find that model errors when using standard left-to-right tokenization follow stereotyped error patterns, suggesting that model computations are systematic rather than approximate. We show that the model is able to convert between tokenizations easily, thus allowing chain-of-thought-inspired approaches to recover performance on left-to-right tokenized inputs. We also find the gap between tokenization directions decreases when models are scaled, possibly indicating that larger models are better able to override this tokenization-dependent inductive bias. In summary, our work performs the first study of how number tokenization choices lead to differences in model performance on arithmetic tasks, accompanied by a thorough analysis of error patterns. We hope this work inspires practitioners to more carefully ablate number tokenization-related choices when working towards general models of numerical reasoning.
研究动机与目标
- 促使对数字分词作为前沿大型语言模型在数值推理中的潜在归纳偏置进行仔细考察。
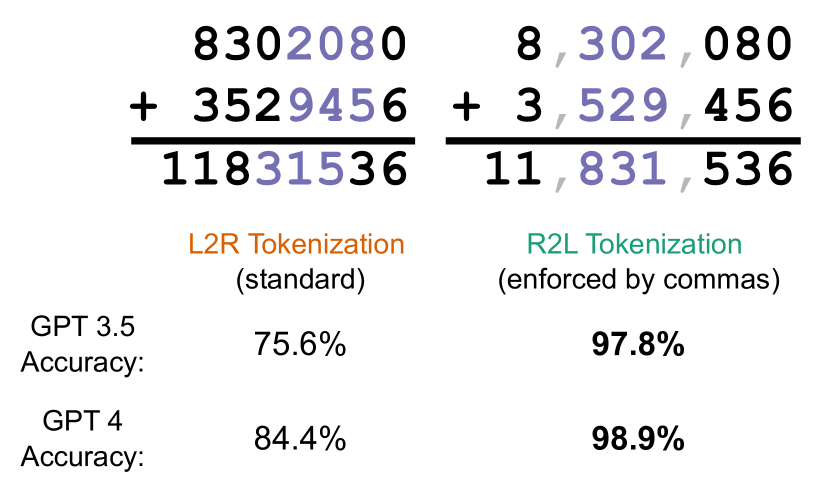
- 比较 GPT-3.5 和 GPT-4 在从左到右(L2R)与从右到左(R2L)分词下的算术性能。
- 分析错误模式以理解分词对推理过程的影响。
- 评估模型规模是否缓解与分词相关的偏差。
提出的方法
- 实验设置使用 OpenAI Chat Completions API 对七到九位加数的少-shot 加法任务进行测试。
- 通过在每三位插入分隔符(逗号或其他定界符)来强制 R2L 分词,从而改变输入分段。
- 在 1、2、4、8-shot 提示下以及在不同模型版本(GPT-3.5、GPT-4及其变体)中测量准确性。
- 进行消融实验以控制格式先验和“思考标记”,包括替代分隔符和将分词方向与输出分离的提示。
- 分析错误模式以描述何时 L2R 分词表现不佳(如长度不匹配的情况)以及错误的性质(数字层面的错误)。
实验结果
研究问题
- RQ1分词方向(L2R 与 R2L)如何影响前沿 LLM 的算术精度?
- RQ2分词引起的效应是否在不同模型版本和更大规模的模型中持续存在?
- RQ3在不同分词方案下出现了哪些错误模式,它们是否表明系统性计算与近似匹配?
- RQ4通过提示模型在分词之间转换输入是否能缓解性能差距?
- RQ5观察到的效应是由分词边界驱动,还是由更广泛的训练数据先验驱动?
主要发现
- 在受控实验中,R2L 分词在 GPT-3.5 和 GPT-4 的算术准确性显著高于 L2R(例如,准确率最高可提升至 20%)。
- R2L 与 L2R 的准确性差距在更多 shot 时扩大,但趋于稳定,R2L 在 8-shot 试验中仍显示出稳健增益。
- 长度不匹配的情况(答案长度大于加数)不成比例地削弱了 L2R 的性能,揭示了输入与输出之间的分词引起的错位。
- L2R 分词在长度不匹配场景中产生高度刻板的数字-4 错误,表明存在系统性处理模式,而非纯噪声。
- 模型可以将 L2R 输入转换为 R2L 输出以恢复准确性,少-shot 提示使模型能够用偏好的分词重复问题。
- 分词依赖效应通常也扩展到更新的模型,包括 GPT-4 变体,尽管在不同模型版本和配置中的幅度可能有所不同。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。