[论文解读] Towards A Unified Agent with Foundation Models
本文提出一个以语言为中心的强化学习框架,利用视觉-语言模型和大语言模型来解决稀疏奖励的机器人堆叠任务,实现高效探索、数据重用、技能调度,以及通过观察学习,无需任务特定的手工设计课程。
Language Models and Vision Language Models have recently demonstrated unprecedented capabilities in terms of understanding human intentions, reasoning, scene understanding, and planning-like behaviour, in text form, among many others. In this work, we investigate how to embed and leverage such abilities in Reinforcement Learning (RL) agents. We design a framework that uses language as the core reasoning tool, exploring how this enables an agent to tackle a series of fundamental RL challenges, such as efficient exploration, reusing experience data, scheduling skills, and learning from observations, which traditionally require separate, vertically designed algorithms. We test our method on a sparse-reward simulated robotic manipulation environment, where a robot needs to stack a set of objects. We demonstrate substantial performance improvements over baselines in exploration efficiency and ability to reuse data from offline datasets, and illustrate how to reuse learned skills to solve novel tasks or imitate videos of human experts.
研究动机与目标
- 探索基础模型如何作为强化学习代理的统一推理骨干。
- 证明在稀疏奖励环境中探索效率的提升。
- 展示离线数据如何被重用于引导序列任务学习。
- 通过语言驱动的目标来说明技能调度和通过观察学习。
提出的方法
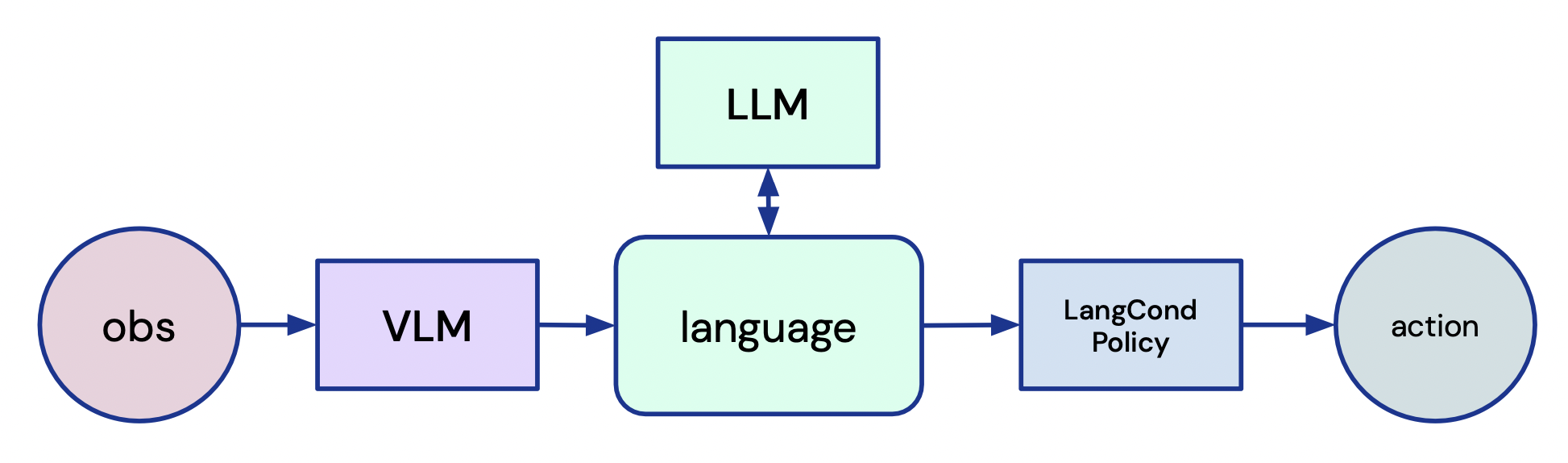
- 通过使用 CLIP 风格的嵌入将观测描述出来,将视觉映射到文本,从而连接视觉与语言。
- 使用微调后的 LLM(FLAN-T5)在不进行额外领域内训练的情况下将任务分解为文本子目标。
- 通过基于变换器的语言条件策略从零开始学习将语言子目标落地为动作。
- 采用 Collect & Infer 循环,由 VLMs 通过将子目标完成情况与观测进行验证来提供内部奖励。
- 运行多分布式代理(N=1000)将数据收集到共享缓冲区,并在 episode 结束后进行行为克隆。
- 通过基于 VLM 的奖励重标注和 CLIP 风格的对齐,使离线数据通过将过去的经验与新任务绑定来重用。
- 通过 VLMs 将专家视频帧映射到子目标并执行相应技能,从而实现从观察学习。
实验结果
研究问题
- RQ1基础模型(LLMs/VLMs)是否能为稀疏奖励设置中的核心 RL 挑战提供统一的方法?
- RQ2语言生成的子目标在没有手工奖励设计的情况下能否有效引导探索与课程生成?
- RQ3离线经验在机器人操作中引导序列任务学习的程度如何被重复利用以提升学习效率?
- RQ4学习到的技能是否可以被调度和重用以解决新任务并实现从观察学习?
主要发现
- 该框架在 Stack Red on Blue 和 Triple Stack 任务上相较仅依赖环境奖励的基线代理实现了显著更快的学习。
- Triple Stack 任务显示出快速学习,而基线由于极度稀疏性(sparseness > 10^6)而陷入停滞。
- 单一框架通过语言驱动的课程实现探索,无需领域特定的奖励工程。
- 来自先前任务的离线数据可以重新标注并重用以引导新任务,加速序列任务学习。
- 通过视频进行的观察学习可以将学习到的技能对齐到子目标,并在新上下文中执行。
- 分布式数据收集(N=1000 代理)结合自我模仿提高样本效率和学习稳定性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。