[论文解读] Towards Building Multilingual Language Model for Medicine
论文引入了 MMedC,一个 25.5B 标记的多语种医疗语料库,一个评估基准 MMedBench,以及开源多语种医疗大模型(MMedLM/MMedLM 2),在 MMedBench 上的表现强劲,堪比 GPT-4。
The development of open-source, multilingual medical language models can benefit a wide, linguistically diverse audience from different regions. To promote this domain, we present contributions from the following: First, we construct a multilingual medical corpus, containing approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, enabling auto-regressive domain adaptation for general LLMs; Second, to monitor the development of multilingual medical LLMs, we propose a multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; Third, we have assessed a number of open-source large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC. Our final model, MMed-Llama 3, with only 8B parameters, achieves superior performance compared to all other open-source models on both MMedBench and English benchmarks, even rivaling GPT-4. In conclusion, in this work, we present a large-scale corpus, a benchmark and a series of models to support the development of multilingual medical LLMs.
研究动机与目标
- 开发一个面向语言多样受众的开源多语种医疗语言模型。
- 构建一个覆盖六种语言的自回归训练大规模多语种医疗语料库(MMedC)。
- 创建一个多语种医疗问答基准(MMedBench),并给出评估多语种医疗推理的理由。
- 评估开源大语言模型以及在 MMedC 上训练的模型,以评估多语种医疗问答与推理生成能力。
提出的方法
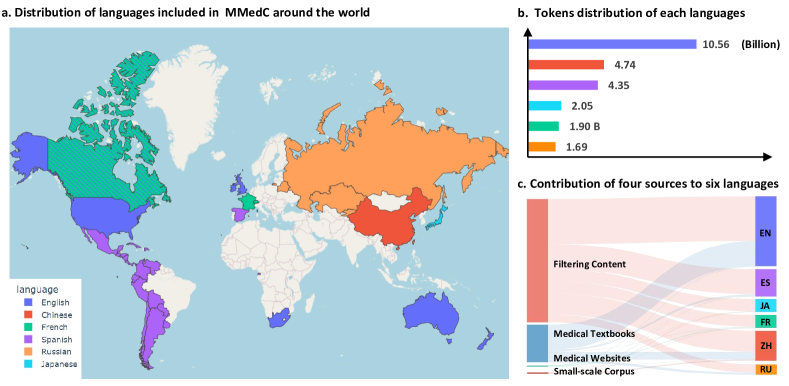
- 从四个数据源汇集超过 25.5B 标记,涵盖英文、中文、日文、法语、俄语和西班牙语。
- 通过聚合多语种医疗选择题 QA 数据集并用 GPT-4 生成的推理来丰富 MMedBench。
- 在零-shot、PEFT 以及全量微调等设置下,对包括在 MMedC 上训练的模型(MMedLM/MMedLM 2)在内的一系列 LLM 进行微调和/或评估。
- 以自动化指标(BLEU-1、ROUGE-1、BERT-score)和人工评估来评估推理质量,以确定可靠的评估方法。
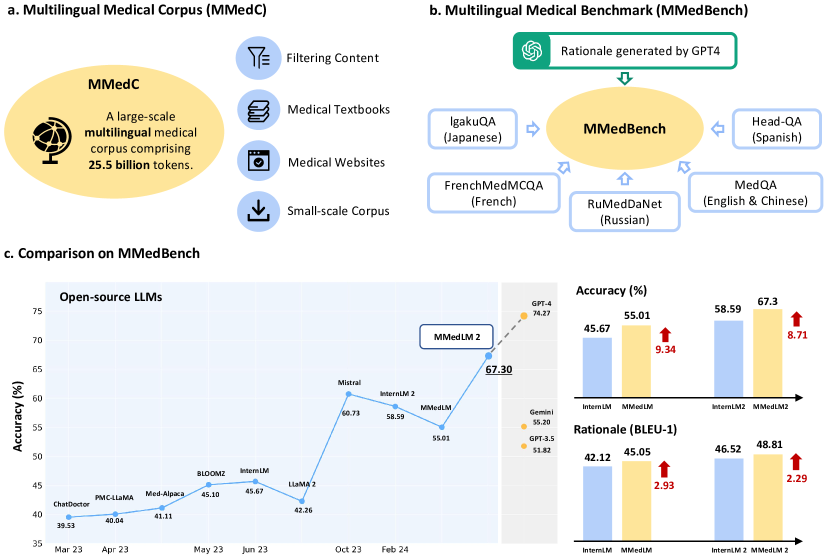
实验结果
研究问题
- RQ1一个多语种、医学聚焦的语料库是否可以提升开源 LLM 对非英语医学查询的表现?
- RQ2在 MMedC 上进行训练对六种语言的多语种医疗问答和推理生成有何影响?
- RQ3哪些评估指标能够最好地反映多语种 LLM 的医学推理的人工判断?
- RQ4开源多语种医疗 LLM 与封闭源模型在 MMedBench 上的相对表现如何?
主要发现
- 在多种设置下,经 MMedC 训练的模型(MMedLM、MMedLM 2)优于基线并在 MMedBench 上与 GPT-4 相当。
- 在六种语言中,MMedLM 2 在多语言全量微调下的准确率从英文 58.13 到西班牙语 80.01 不等,平均在多语言轨道上达到 67.30。
- 推理生成受益于在 MMedC 上的训练,BLEU-1 和 ROUGE-1 分数以及人工评价均对 MMedLM 2 表现有利。
- ROUGE-1 和 BLEU-1 被认定为评估 MMedBench 推理的可靠自动指标,GPT-4 的评分与人工判断的相关性最高,但并不易于大规模扩展。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。