[论文解读] Towards Coding Social Science Datasets with Language Models
GPT-3 可以充当社会科学文本编码的合成编码员,能够与人工编码者匹配并媲美有监督的机器学习,在多任务中通过少样本提示实现高效。
Researchers often rely on humans to code (label, annotate, etc.) large sets of texts. This kind of human coding forms an important part of social science research, yet the coding process is both resource intensive and highly variable from application to application. In some cases, efforts to automate this process have achieved human-level accuracies, but to achieve this, these attempts frequently rely on thousands of hand-labeled training examples, which makes them inapplicable to small-scale research studies and costly for large ones. Recent advances in a specific kind of artificial intelligence tool - language models (LMs) - provide a solution to this problem. Work in computer science makes it clear that LMs are able to classify text, without the cost (in financial terms and human effort) of alternative methods. To demonstrate the possibilities of LMs in this area of political science, we use GPT-3, one of the most advanced LMs, as a synthetic coder and compare it to human coders. We find that GPT-3 can match the performance of typical human coders and offers benefits over other machine learning methods of coding text. We find this across a variety of domains using very different coding procedures. This provides exciting evidence that language models can serve as a critical advance in the coding of open-ended texts in a variety of applications.
研究动机与目标
- 推动用语言模型替代或补充人工编码,以降低社会科学文本编码的成本和变异性。
- 展示GPT-3在不同数据集和编码方案下无需微调即可进行编码的能力。
- 将GPT-3的编码表现与人工编码者以及传统有监督机器学习方法进行比较。
- 评估GPT-3在各任务中的编码可靠性(互编者一致性)与效率(时间/成本)。
提出的方法
- 为GPT-3提供带有两到三个示例的任务特定提示,以教授编码任务。
- 将GPT-3输出转换为分类或序数编码,并使用互编者可靠性指标与人工编码者进行比较。
- 使用四个数据集(PP、CAP-Congress、CAP-NYT、TGP)在领域、数据结构和测量类型上测试编码。
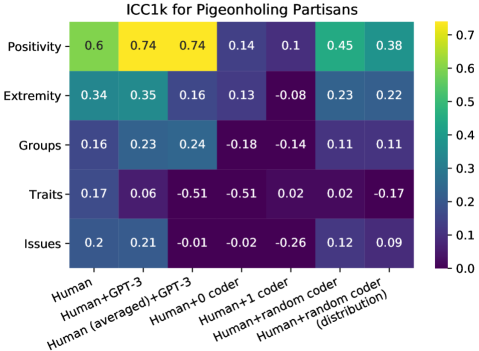
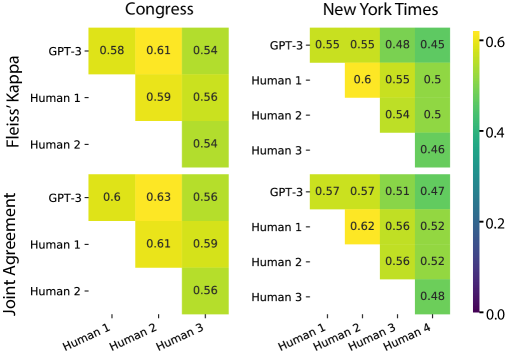
- 计算组内相关系数(ICC)、一致性联合概率,以及Fleiss’ κ以量化GPT-3与人类之间的一致性。
- 对GPT-3类别概率进行校准,以在可能存在多类别时考虑模型偏差(可选,适度增益)。
实验结果
研究问题
- RQ1在不进行微调的前提下,GPT-3是否能在少量示例提示下以与人类编码者相当的性能对社会科学文本进行编码?
- RQ2在不同数据集上,GPT-3的编码可靠性(ICC、κ、联合一致性)与人工编码者及有监督的机器学习基线相比如何?
- RQ3提示设计和示例选择是否会显著影响GPT-3的编码准确性和可靠性?
- RQ4使用GPT-3进行大规模文本编码相对于传统人工或机器学习方法的效率和成本含义是什么?
- RQ5与人类相比,GPT-3在领域特定或类别特定的编码表现是否存在模式?
主要发现
- GPT-3在平均水平上能够在序数和分类编码任务中达到与人类编码者相当的表现,仅需2–3个示例。
- GPT-3在若干属性上相较于单独由人类编码的编码,提高互编者一致性(ICC),尽管并非在所有类别上均如此。
- GPT-3的表现与有监督的基线方法具有竞争力,在标注示例显著较少的情况下实现了较高的准确性(例如4个示例对比数千个)。
- 在四个数据集(PP、CAP-Congress、CAP-NYT、TGP)中,GPT-3与人类之一致在许多情况下与人-人一致性相当,任务和类别存在一定变异。
- 对GPT-3概率进行校准可带来适度的准确性提升(约4–5%)。
- 在Guardian Populism数据中,GPT-3与人类的ICC约为0.77(人类为0.81),在4个示例的情况下获得约79%的人工编码准确度,而基于词袋的ML方法在数千个标注示例下达到约86%的准确性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。