[论文解读] Towards Generalist Biomedical AI
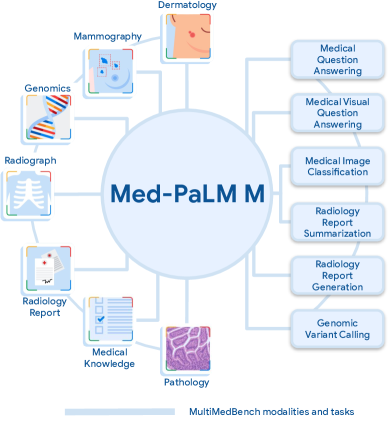
本文介绍 MultiMedBench,一个14任务的多模态生物医学基准,以及 Med-PaLM M,一个在所有任务上无需任务特定微调就达到SOTA或接近SOTA表现的通用多模态模型。它还提供零-shot泛化、任务迁移证据,以及放射科医师对胸部X光报告的评估对齐证据。
Medicine is inherently multimodal, with rich data modalities spanning text, imaging, genomics, and more. Generalist biomedical artificial intelligence (AI) systems that flexibly encode, integrate, and interpret this data at scale can potentially enable impactful applications ranging from scientific discovery to care delivery. To enable the development of these models, we first curate MultiMedBench, a new multimodal biomedical benchmark. MultiMedBench encompasses 14 diverse tasks such as medical question answering, mammography and dermatology image interpretation, radiology report generation and summarization, and genomic variant calling. We then introduce Med-PaLM Multimodal (Med-PaLM M), our proof of concept for a generalist biomedical AI system. Med-PaLM M is a large multimodal generative model that flexibly encodes and interprets biomedical data including clinical language, imaging, and genomics with the same set of model weights. Med-PaLM M reaches performance competitive with or exceeding the state of the art on all MultiMedBench tasks, often surpassing specialist models by a wide margin. We also report examples of zero-shot generalization to novel medical concepts and tasks, positive transfer learning across tasks, and emergent zero-shot medical reasoning. To further probe the capabilities and limitations of Med-PaLM M, we conduct a radiologist evaluation of model-generated (and human) chest X-ray reports and observe encouraging performance across model scales. In a side-by-side ranking on 246 retrospective chest X-rays, clinicians express a pairwise preference for Med-PaLM M reports over those produced by radiologists in up to 40.50% of cases, suggesting potential clinical utility. While considerable work is needed to validate these models in real-world use cases, our results represent a milestone towards the development of generalist biomedical AI systems.
研究动机与目标
- 推动开发能够整体处理多种数据模态和任务的通用生物医学AI系统。
- 创建并发布 MultiMedBench,一个涵盖文本、影像和基因组学的多样化基准,包含14个任务。
- 提出 Med-PaLM M,一个具有统一生成框架的单一模型,在不进行任务特定微调的情况下解决多种生物医学任务。
- 展示对专业模型的强劲表现并探索出现的零-shot泛化和临床评估。
提出的方法
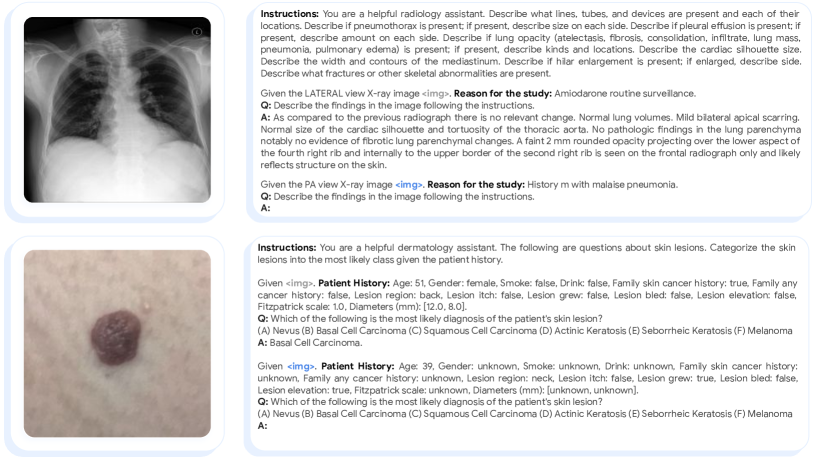
- 利用基于 PaLM-E 的通用架构,在视觉-语言数据上进行预训练,并在生物医学数据上进行微调。
- 通过任务特定提示和一-shot 示例进行指令微调,将多样任务统一到一个输出空间。
- 在多模态上下文中将图像令牌与文本交错,并使用与任务数据量成比例的混合比在 MultiMedBench 上端到端训练。
- 在模型尺度(12B、84B、562B)上评估,以研究规模扩大对语言仅任务和多模态推理任务的影响。
- 对 AI 生成的胸部 X 光报告进行放射科医生评估,并在 MIMIC-CXR 上与人类参考进行比较。
实验结果
研究问题
- RQ1在这些任务上,是否可以用一个在多样生物医学任务上训练的单一多模态模型达到与专业模型相竞争甚至更优的表现?
- RQ2模型规模的扩展是否比静态图像分类任务更能提升对语言密集型和多模态推理任务的表现?
- RQ3在通用生物医学AI中,关于零-shot 泛化和新兴的多模态医学推理有哪些证据?
- RQ4在不同模型尺度下,放射科医生对 AI 生成的胸部 X 光报告的评估与人类参考相比如何?
- RQ5通用模型是否能在生物医学领域的任务之间展示积极迁移?
主要发现
- Med-PaLM M 在所有 MultiMedBench 任务上匹配或超过 SOTA,通常以单一权重集优于专业模型。
- 胸部 X-ray 报告生成在 MIMIC-CXR 上的 micro-F1 提升超过 8%,超过先前的 SOTA。
- 在 Slake-VQA 上,Med-PaLM M 在 BLEU-1 和 F1 指标上领先前一代 SOTA 超过 10%。
- 观察到零-shot 和新兴能力,包括零-shot 医学推理和对新概念的泛化。
- 放射科医生评估显示 Med-PaLM M 的报告在多达 40.50% 的情况下更受偏好,最佳模型每份报告的临床显著错误为 0.25。
- 模型规模对语言密集型和视觉推理任务显示显著提升,但对某些以图像为主的任务回报递减。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。