[论文解读] Towards Generalist Foundation Model for Radiology by Leveraging Web-scale 2D&3D Medical Data
RadFM 引入 MedMD 和 RadMD 来训练一个可视化条件的放射学基础模型,在 RadBench 上评估,并在多项放射学任务上超越公开基线。
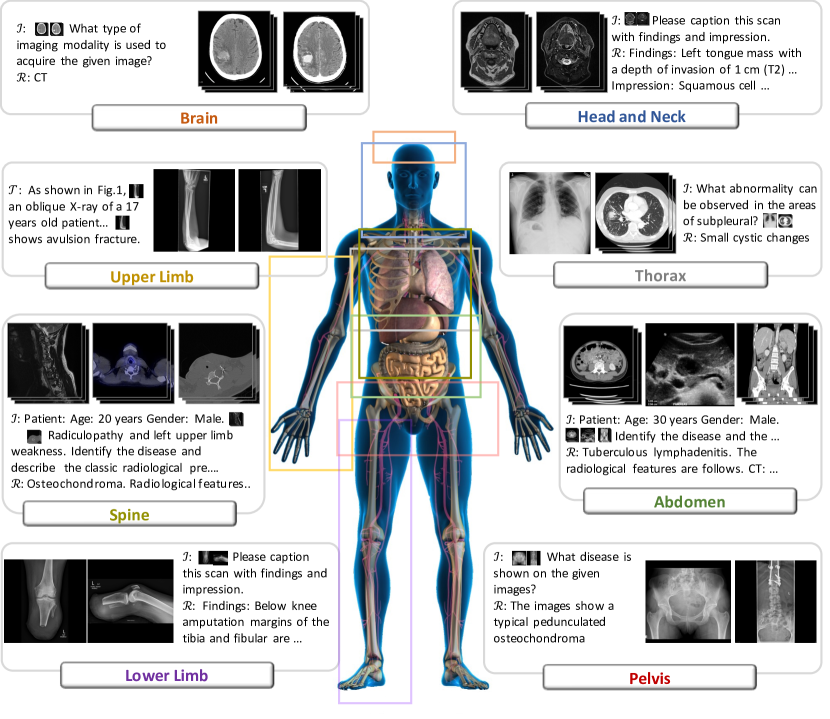
In this study, we aim to initiate the development of Radiology Foundation Model, termed as RadFM. We consider the construction of foundational models from three perspectives, namely, dataset construction, model design, and thorough evaluation. Our contribution can be concluded as follows: (i), we construct a large-scale Medical Multi-modal Dataset, MedMD, which consists of 16M 2D and 3D medical scans with high-quality text descriptions or reports across various data formats, modalities, and tasks, covering over 5000 distinct diseases. To the best of our knowledge, this is the first large-scale, high-quality, medical visual-language dataset, with both 2D and 3D scans; (ii), we propose an architecture that enables visually conditioned generative pre-training, i.e., allowing for integration of text input with 2D or 3D medical scans, and generate responses for diverse radiologic tasks. The model was initially pre-trained on MedMD and subsequently fine-tuned on the domain-specific dataset, which is a radiologic cleaned version of MedMD, containing 3M radiologic visual-language pairs, termed as RadMD; (iii), we propose a new evaluation benchmark, RadBench, that comprises five tasks, including modality recognition, disease diagnosis, visual question answering, report generation and rationale diagnosis, aiming to comprehensively assess the capability of foundation models in handling practical clinical problems. We conduct both automatic and human evaluation on RadBench, in both cases, RadFM outperforms existing multi-modal foundation models, that are publicaly accessible, including Openflamingo, MedFlamingo, MedVInT and GPT-4V. Additionally, we also adapt RadFM for different public benchmarks, surpassing existing SOTAs on diverse datasets. All codes, data, and model checkpoint will all be made publicly available to promote further research and development in the field.
研究动机与目标
- 解决放射学领域基础模型缺乏大规模多模态医学数据的问题。
- 构建一个大规模、高质量的放射学聚焦多模态数据集(MedMD),以及一个干净的微调子集(RadMD)。
- 开发一个统一的、可视化条件的生成模型(RadFM),能够处理 2D 和 3D 医学图像与文本。
- 建立一个全面的评估基准(RadBench),用于评估模态识别、疾病诊断、VQA、报告生成和推理诊断。
- 证明 RadFM 在现有公开多模态基础模型上的性能提升,并适配到其他基准。
提出的方法
- 使用 16M 的 2D/3D 放射学扫描以及跨 17 个系统和 5000+ 种疾病的高质量文本描述或报告来构建 MedMD。
- 通过筛选 MedMD 来获得一个 3M 的面向放射学的视觉语言数据集,以用于领域特定微调。
- 提出 RadFM,一个使用 3D ViT 视觉编码器、Perceiver 聚合模块以及用于文本生成的 LLM 的可视化条件自回归模型。
- 通过将 2D 图像填充为 4 个切片并对 3D 补丁使用可学习的位置嵌入,来实现多图像输入。
- 使用基于 Perceiver 的融合来聚合视觉嵌入,与文本提示交错;采用负对数似然目标进行训练。
- 对每个标记应用权重,强调医学术语和相关提示,对交错数据集与视觉-指令数据集的权重有所不同。
- 对模态识别、疾病诊断、VQA、报告生成和推理诊断等任务,利用面向任务的提示来塑造输出。
![Figure 1 : The general comparison between RadFM and different SOTA methods, i.e. , OpenFlamingo [ 1 ] , MedVInT [ 55 ] , Med-Flamingo [ 31 ] and GPT-4V [ 37 ] . On the left we plot the radar figure of the five models, on the average of different automatic metrics, the coordinate axes are logarithmiz](https://ar5iv.labs.arxiv.org/html/2308.02463/assets/x1.png)
实验结果
研究问题
- RQ1一个通用且单一模型是否能够有效处理多样的放射学任务(模态识别、疾病诊断、VQA、报告生成、推理诊断),使用 2D/3D 输入和自然语言输出?
- RQ2在对大规模 MedMD 数据集进行训练并随后进行放射学聚焦微调(RadMD)后,是否比现有公开多模态放射学模型有更好的性能?
- RQ3RadFM 在全面的放射学特定基准(Radbench)以及 Radbench 之外的公开基准上表现如何?
- RQ4哪些架构选择(3D ViT 编码器、Perceiver 融合、LLM 解码器)有助于统一 2D/3D 放射学数据和多样任务?
- RQ5数据质量和提示策略对放射学任务的模型性能有何影响?
主要发现
- RadFM 在 RadBench 上超过公开可用的多模态基础模型(OpenFlamingo、MedFlamingo、MedVInT、GPT-4V)在自动评估和人工评估上的表现。
- RadFM 在适配到 Radbench 之外的公开基准时显示出强泛化能力。
- RadFM 是首个将 2D 与 3D 放射学图像统一在单一架构中的基础模型。
- 该模型支持多图像输入,并为多种放射学任务生成自然语言输出。
- 训练管道将广泛的 MedMD 预训练数据集与面向放射学的 RadMD 微调集相结合,以实现强大的领域对齐。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。