[论文解读] Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language
LENS 通过从独立视觉模块获得文本描述来使冻结的语言模型“看见”,在不需要多模态预训练的情况下实现具有竞争力的零-shot 视觉与视觉-语言任务。
We propose LENS, a modular approach for tackling computer vision problems by leveraging the power of large language models (LLMs). Our system uses a language model to reason over outputs from a set of independent and highly descriptive vision modules that provide exhaustive information about an image. We evaluate the approach on pure computer vision settings such as zero- and few-shot object recognition, as well as on vision and language problems. LENS can be applied to any off-the-shelf LLM and we find that the LLMs with LENS perform highly competitively with much bigger and much more sophisticated systems, without any multimodal training whatsoever. We open-source our code at https://github.com/ContextualAI/lens and provide an interactive demo.
研究动机与目标
- 在没有多模态预训练的情况下,激发并实现对冻结 LLM 的视觉推理。
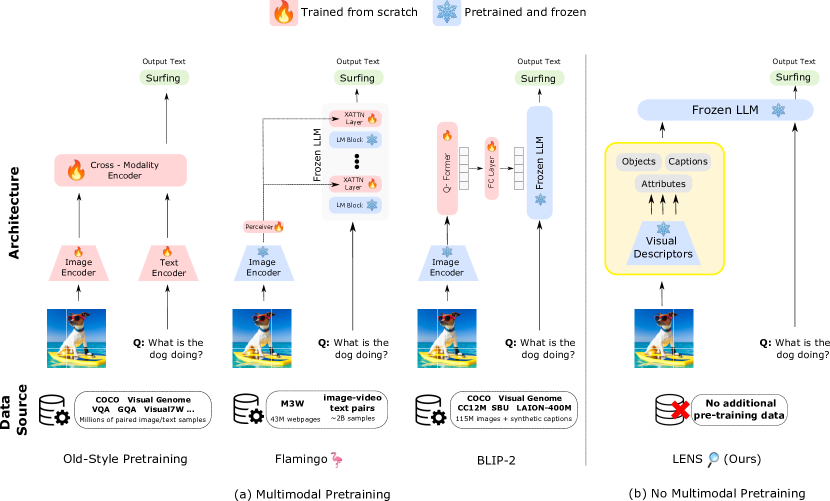
- 提出一种将视觉模块与冻结 LLM 作为推理引擎耦合的模块化体系结构(LENS)。
- 展示 LENS 在多样数据集上对对象识别与视觉-语言任务的零-shot 表现具有竞争力。
提出的方法
- 定义用于描述图像的视觉词汇(标签和属性)。
- 使用三个视觉模块(Tag、Attributes、Intensive Captioning)从图像生成文本描述。
- 将拼接后的文本描述输入冻结的 LLM 以执行对象识别和 V&L 任务。
- 设计将视觉模块输 出与用户查询以及简短的最终答案提示结合的任务特定提示。
- 在零-shot 和少样本的对象识别以及零-shot 的 VQA/OK-VQA/仇恨表情 Meme 基准上进行评估,并与多模态基线进行比较。
实验结果
研究问题
- RQ1在没有多模态预训练的情况下,由独立视觉模块提供文本描述来引导冻结的 LLM,是否能够实现具有竞争力的视觉与视觉-语言任务?
- RQ2不同视觉模块(标签、属性、描述)对零-shot 对象识别与 V&L 推理性能的贡献是什么?
- RQ3LENS 与联合预训练的多模态模型在标准视觉基准和 VQA 风格任务上有何差异?
- RQ4哪些提示及提示组件最能利用文本化的视觉信息进行基于 LLM 的推理?
主要发现
| 模型 | 可训练参数数量 | VQAv2(test-dev) | OK-VQA(test) | Rendered-SST2(test) | Hateful Memes(dev) |
|---|---|---|---|---|---|
| Kosmos-1 | 1.6B | 51.0 | - | 67.1 | 63.9 |
| Flamingo 3B | 1.4B | 49.2 | 41.2 | - | 53.7 |
| Flamingo 9B | 1.8B | 51.8 | 44.7 | - | 57.0 |
| Flamingo 80B | 10.2B | 56.3 | 50.6 | - | 46.4 |
| BLIP-2 ViT-L FlanT5 XL | 103M | 62.3 | 39.4 | - | - |
| BLIP-2 ViT-g FlanT5 XXL | 108M | 65.0 | 45.9 | - | - |
| LENS Flan-T5 XL | 0 | 57.9 | 32.8 | 83.3 | 58.0 |
| LENS Flan-T5 XXL | 0 | 62.6 | 43.3 | 82.0 | 59.4 |
- LENS 在对端到端预训练模型如 Kosmos 与 Flamingo 的零-shot 对象识别方面实现了具有竞争力的性能。
- 在视觉与语言任务中,LENS 搭配 Flan-T5 XXL 在 VQA 2.0 及相关基准上取得优越或具竞争力的结果,相较于若干多模态基线。
- 将标签与属性信息结合能够为对象识别提供互补的增益,优于仅使用单一视觉模块。
- 对 VQA 的结果,Intensive captioning 提升明显,但在某些描述数量达到一定阈值后收益递减;将 OCR 基于的提示与标签和属性结合时,对仇恨 Meme 任务有帮助。
- LENSOO(最佳变体)展示出强大的零-shot 性能,同时避免多模态预训练,突出模块化、基于推理的 LLM 使用的有效性。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。