[论文解读] Towards Measuring the Representation of Subjective Global Opinions in Language Models
该论文从跨国调查构建 GlobalOpinionQA,并提出一种用于将 LLM 回应与人类的国家特定意见进行比较度量的方法,揭示对 WEIRD 群体的偏见以及提示与语言对 representation 的影响。
Large language models (LLMs) may not equitably represent diverse global perspectives on societal issues. In this paper, we develop a quantitative framework to evaluate whose opinions model-generated responses are more similar to. We first build a dataset, GlobalOpinionQA, comprised of questions and answers from cross-national surveys designed to capture diverse opinions on global issues across different countries. Next, we define a metric that quantifies the similarity between LLM-generated survey responses and human responses, conditioned on country. With our framework, we run three experiments on an LLM trained to be helpful, honest, and harmless with Constitutional AI. By default, LLM responses tend to be more similar to the opinions of certain populations, such as those from the USA, and some European and South American countries, highlighting the potential for biases. When we prompt the model to consider a particular country's perspective, responses shift to be more similar to the opinions of the prompted populations, but can reflect harmful cultural stereotypes. When we translate GlobalOpinionQA questions to a target language, the model's responses do not necessarily become the most similar to the opinions of speakers of those languages. We release our dataset for others to use and build on. Our data is at https://huggingface.co/datasets/Anthropic/llm_global_opinions. We also provide an interactive visualization at https://llmglobalvalues.anthropic.com.
研究动机与目标
- 创建一个用于评估的跨国意见数据集(GlobalOpinionQA),来源于 PEW GAS 与 World Values Survey。
- 定义一个按国家条件的相似度度量,以比较 LLM 输出与人类回答。
- 评估默认提示、跨国提示与语言提示如何影响全球意见的表示。
- 调查对特定人群的偏见,以及语言与提示对表示的影响。
- 讨论局限性和潜在干预措施,以改善 LLM 的包容性表示。
提出的方法
- 从 PEW GAS 与 WVS Wave 7 汇集 2,556 道选择题,构建 GlobalOpinionQA。
- 记录模型在每道题对各选项的预测概率。
- 通过在每个国家内对回答进行平均,计算按国家的人类回答概率。
- 使用 1 - Jensen-Shannon Distance 作为模型与国家回答之间的相似度度量。
- 进行三种提示实验:默认提示、跨国提示、语言提示。
- 将提示翻译为俄语、中文和土耳其语,以测试语言效应并与母语者校验翻译。

实验结果
研究问题
- RQ1在多大程度上经过 RLHF/宪法 AI 调整的 LLM 回答与 PEW 与 WVS 捕捉的国家特定意见相一致?
- RQ2提示策略(默认、跨国、语言)如何使模型的对齐程度偏向不同国家的意见?
- RQ3将提示翻译成目标语言是否会提升与主要以该语言为母语的群体的对齐度?
- RQ4将模型观点引导至特定文化视角的限制与潜在危害有哪些?
- RQ5哪些干预措施可以提高 LLM 对全球多样观点的包容性表示?
主要发现
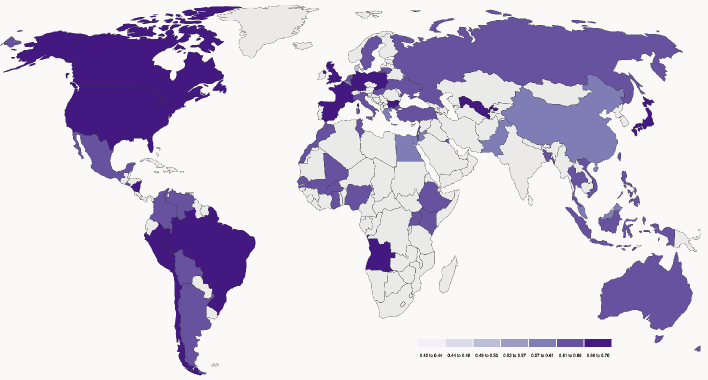
- 默认提示更易与 WEIRD 人口(美国、加拿大、澳大利亚、某些欧洲和南美国家)保持较高相似性。
- 跨国提示能将模型输出引导至所提示国家的意见,但也可能揭示有害的文化刻板印象和表层理解。
- 语言提示对回应的影响低于预期;翻译成俄语、中文和土耳其语未始终提升与相应语言人口的对齐度。
- 模型生成可能对全球多样性缺乏充分体现,表现出高度置信的狭窄回应,表明校准与表示的差距。
- 提示差异揭示潜在偏见,以及模型需要更深入的社会语境理解。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。