[论文解读] Towards Mitigating Hallucination in Large Language Models via Self-Reflection
本论文分析医疗领域生成性问答中的幻觉现象,并提出一个互动式自我反思循环,以生成、评估和完善背景知识及答案,从而在多个大型语言模型和数据集上减少幻觉。
Large language models (LLMs) have shown promise for generative and knowledge-intensive tasks including question-answering (QA) tasks. However, the practical deployment still faces challenges, notably the issue of "hallucination", where models generate plausible-sounding but unfaithful or nonsensical information. This issue becomes particularly critical in the medical domain due to the uncommon professional concepts and potential social risks involved. This paper analyses the phenomenon of hallucination in medical generative QA systems using widely adopted LLMs and datasets. Our investigation centers on the identification and comprehension of common problematic answers, with a specific emphasis on hallucination. To tackle this challenge, we present an interactive self-reflection methodology that incorporates knowledge acquisition and answer generation. Through this feedback process, our approach steadily enhances the factuality, consistency, and entailment of the generated answers. Consequently, we harness the interactivity and multitasking ability of LLMs and produce progressively more precise and accurate answers. Experimental results on both automatic and human evaluation demonstrate the superiority of our approach in hallucination reduction compared to baselines.
研究动机与目标
- 使用多种LLM和医疗问答数据集,考察医疗生成式问答系统中幻觉的发生率和性质。
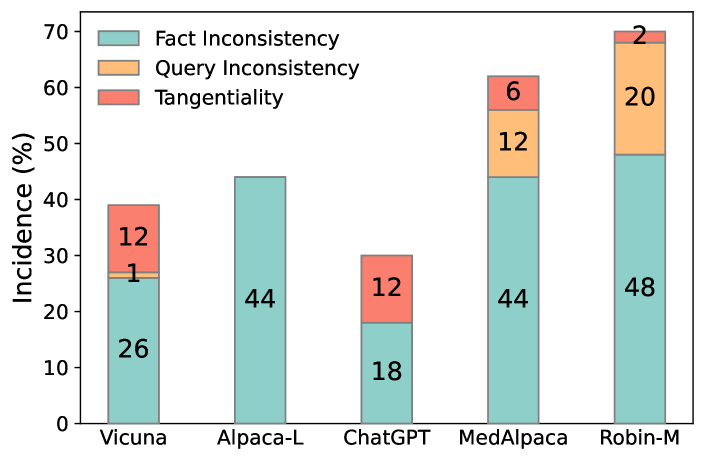
- 调查造成幻觉的原因,如事实不一致、查询不一致以及回答的偏离性(旁推)等。
- 提出并评估一个自我反思工作流,该工作流迭代地产生、评分并完善知识和答案,以提升事实可靠性。
- 评估该方法在不同参数量模型(7B 和 175B)上的泛化性和可扩展性。
提出的方法
- 提出一个具有三重循环的迭代式自我反思管线:获取真实世界知识、知识一致的回答,以及问题蕴涵性回答。
- 使用生成-评分-修正循环,其中事实性评分器评估生成的背景知识,并提示修正,直到事实性达到阈值。
- 在经过精炼知识的条件下生成答案,然后使用 CTRLEval 评估与背景知识的一致性,如有需要再提示修正。
- 使用句子级检查在答案与问题之间纳入蕴涵评估,以确保可回答性。
- 同时评估自动指标(MedNLI、CtrlEval、F1、ROUGE-L 等)和人类判断(查询一致性、旁推、事实一致性)。

实验结果
研究问题
- RQ1医学GQA中幻觉在通用与医学领域LLM中的发生率与性质为何?
- RQ2互动式自我反思循环是否能减少幻觉、提升事实性、一致性和蕴涵性?
- RQ3所提出方法在不同参数量的模型以及多个人工医疗问答数据集上的表现如何?
- RQ4精炼、方面描述与显式评分对该循环有效性的贡献是什么?
主要发现
- 相较基线,自我反思循环减少了生成的医疗问答回复中的查询不一致、旁推以及事实不一致。
- 该方法在多种模型和五个医疗数据集上提升了 MedNLI 及相关的蕴涵性和一致性指标。
- 人类评估显示使用该循环时幻觉更少、与所提供知识的一致性更高。
- 消融研究表明,精炼步骤、显式方面描述以及评分信号有助于提升事实性和对齐性。
- 该方法在多样的医疗问答任务中对 7B 和 175B 模型表现出良好的泛化性和可扩展性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。