[论文解读] Towards Personalized Federated Learning via Heterogeneous Model Reassembly
本文提出 pFedHR,一种在服务器重新组装候选模型并将其匹配到各客户端,同时不泄露私有数据的异构客户端模型个性化联邦学习框架。它能够自动生成多样化的个性化候选模型,并通过层拼接和基于相似度的选择来缓解公共数据分布问题。
This paper focuses on addressing the practical yet challenging problem of model heterogeneity in federated learning, where clients possess models with different network structures. To track this problem, we propose a novel framework called pFedHR, which leverages heterogeneous model reassembly to achieve personalized federated learning. In particular, we approach the problem of heterogeneous model personalization as a model-matching optimization task on the server side. Moreover, pFedHR automatically and dynamically generates informative and diverse personalized candidates with minimal human intervention. Furthermore, our proposed heterogeneous model reassembly technique mitigates the adverse impact introduced by using public data with different distributions from the client data to a certain extent. Experimental results demonstrate that pFedHR outperforms baselines on three datasets under both IID and Non-IID settings. Additionally, pFedHR effectively reduces the adverse impact of using different public data and dynamically generates diverse personalized models in an automated manner.
研究动机与目标
- 解决在客户端网络结构不同的联邦学习中的模型异质性问题。
- 开发一个服务器端机制,在不共享私有数据的前提下生成并选择个性化模型。
- 通过异质模型重组降低对公共数据分布的依赖并提升个性化效果。
- 在多数据集上展示在 IID 和 Non-IID 设置下相对于基线的更优性能。
提出的方法
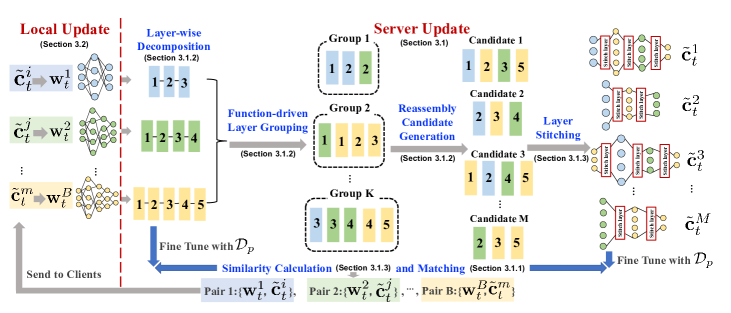
- 将每个客户端模型分解为层,并使用基于 CKA 的相似性度量按功能对层进行分组。
- 通过逐层分解、按功能分组以及带层拼接的重组,生成 M 个异质模型候选。
- 使用公开数据计算每个客户端模型与拼接候选的相似性,以及微调后对数层输出的余弦相似度。
- 为每个客户端选择最匹配的候选作为本轮的个性化模型,并通过知识蒸馏在客户端学习中用作指导。
- 使用少量轮次对拼接候选进行微调以利用公开数据并限制不良影响;使用带标签或无标签的公开数据作为指导,但避免过度参数共享。
- 客户端更新使用知识蒸馏将个性化模型整合到本地训练中,保护客户端数据隐私。

实验结果
研究问题
- RQ1通过服务器端模型重组在不暴露私有数据的前提下,是否可以有效对异质客户端模型进行个性化?
- RQ2在具有异构架构的联邦学习中,如何自动生成信息丰富且多样化的个性化模型候选并匹配到客户端?
主要发现
| 公开数据 | 数据集 | MNIST IID | MNIST Non-IID | SVHN IID | SVHN Non-IID | CIFAR-10 IID | CIFAR-10 Non-IID |
|---|---|---|---|---|---|---|---|
| Labeled | MNIST | 93.08% | 91.44% | 81.55% | 78.39% | 68.22% | 66.13% |
| Labeled | SVHN | 94.10% | 93.27% | 81.94% | 81.06% | 72.69% | 70.27% |
| Labeled | pFedHR | 94.55% | 94.41% | 83.68% | 83.40% | 73.88% | 71.74% |
| Unlabeled | FedKEMF | 93.01% | 91.66% | 80.41% | 79.33% | 67.12% | 66.93% |
| Unlabeled | FCCL | 93.62% | 92.88% | 82.03% | 79.75% | 68.77% | 66.49% |
| Unlabeled | pFedHR | 93.89% | 93.76% | 83.15% | 80.24% | 69.38% | 68.01% |
- 在异构模型实验中,pFedHR 在 IID 和 Non-IID 设置下对 MNIST、SVHN 和 CIFAR-10 实现了最先进的性能。
- 在公开数据带标签的情况下,pFedHR 在所有数据集和设置中始终优于基线。对于 MNIST:93.08% vs 93.24%(FedGH)和 94.55%(pFedHR);对于 SVHN:81.55%(FedMD) vs 83.68%(pFedHR);对于 CIFAR-10:68.22%(FedMD) vs 73.88%(pFedHR)。
- 在无标签公开数据的情况下,pFedHR 仍然具竞争力,且常常优于基线,例如 MNIST 93.89% IID vs 93.01%(FedKEMF);SVHN 83.15% IID vs 82.03%(FCCL);CIFAR-10 69.38% IID vs 68.77%(FCCL)。
- 当公开数据分布与客户端数据不同时时,该框架仍保持性能,显示出对公开数据敏感性的鲁棒性。
- 增加聚类数 K 能提升性能,但需要与生成的候选数 M 进行权衡。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。