[论文解读] Towards Translating Real-World Code with LLMs: A Study of Translating to Rust
本论文研究使用 Flourine 将真实世界的 C/Go 代码翻译成 Rust 的端到端翻译工具,具跨语言微差分模糊测试,在五个 LLMs 和 408 个基准上(总共 8160 次实验),报告每个模型的翻译成功率。
Large language models (LLMs) show promise in code translation - the task of translating code written in one programming language to another language - due to their ability to write code in most programming languages. However, LLM's effectiveness on translating real-world code remains largely unstudied. In this work, we perform the first substantial study on LLM-based translation to Rust by assessing the ability of five state-of-the-art LLMs, GPT4, Claude 3, Claude 2.1, Gemini Pro, and Mixtral. We conduct our study on code extracted from real-world open source projects. To enable our study, we develop FLOURINE, an end-to-end code translation tool that uses differential fuzzing to check if a Rust translation is I/O equivalent to the original source program, eliminating the need for pre-existing test cases. As part of our investigation, we assess both the LLM's ability to produce an initially successful translation, as well as their capacity to fix a previously generated buggy one. If the original and the translated programs are not I/O equivalent, we apply a set of automated feedback strategies, including feedback to the LLM with counterexamples. Our results show that the most successful LLM can translate 47% of our benchmarks, and also provides insights into next steps for improvements.
研究动机与目标
- 开发 Flourine,一个端到端的 Rust 翻译工具,在没有手写测试用例的情况下验证翻译。
- 评估 LLMs 将真实世界代码从 C/Go 翻译为 Rust 并保持行为的一致性。
- 研究反馈策略和基于编译的修复在实现正确翻译方面的有效性。
- 提供一个跨语言差分模糊测试框架,以验证源程序与翻译后程序之间的 I/O 等价性。
- 开放源代码数据、基准和结果,以实现可重复性。
提出的方法
- Flourine 执行迭代翻译:从 LLM 获得一个候选的 Rust 翻译,修复编译错误,并通过跨语言差分模糊测试器验证 I/O 等价性。
- 模糊测试器使用 JSON 序列化在 Go/C 源代码与 Rust 之间映射程序状态,从而在没有现成测试的情况下进行输入/输出等价性检查。
- 当模糊测试器发现对立例时使用反馈策略来改进翻译;策略包括 restart、hinted restart、counterexample-guided repair,以及 conversational repair。
- 基准从七个真实世界项目(C 和 Go)提取为可编译的 Rust 等价单元,包含 1–25 个函数和多样化领域。
- 实验总计 8160 次运行,覆盖 408 个基准和五个 LLMs(GPT-4-Turbo, Claude 2.1, Claude 3 Sonnet, Gemini Pro, Mixtral)。
- LLMs 在零样本翻译任务下进行提示,随后进行由 Rust 编译器错误引导的编译修复步骤。
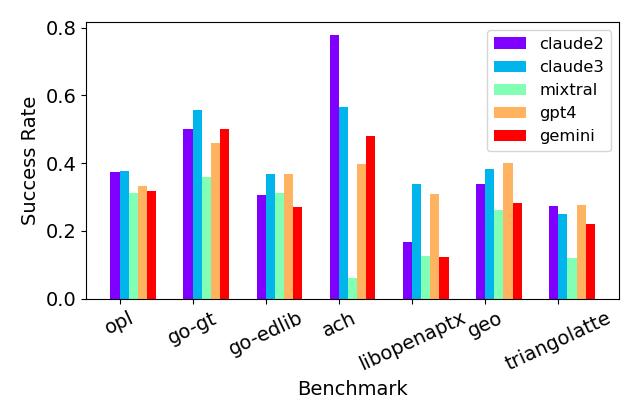
实验结果
研究问题
- RQ1LLMs 在不同基准上将真实世界的 C/Go 代码准确翻译为 Rust 的能力如何?
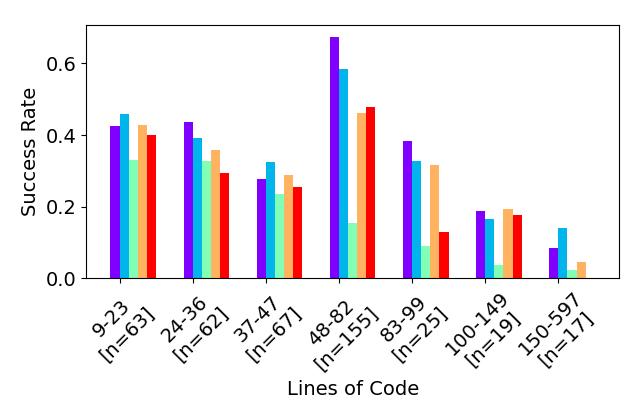
- RQ2程序大小和复杂性如何影响翻译成功率?
- RQ3反馈策略是否能提高翻译成功率,哪些策略最有效?
- RQ4LLM 翻译在质量和地道性方面与基于规则的翻译工具相比如何?
- RQ5翻译失败的主要原因是什么,如何减轻失败?
主要发现
- LLMs 的总体翻译成功率分别是 47.7%(Claude 2),43.9%(Claude 3),21.0%(Mixtral),36.9%(GPT-4-Turbo),和 33.8%(Gemini Pro)。
- 在 408 个基准上,总实验次数为 8160 次,涵盖 408 个基准和五个 LLMs,产生所报告的成功率。
- 表现最佳的 LLM 在多达 47% 的基准上完成翻译,小基准通常比大基准更易翻译。
- 反馈策略在最佳 LLMs 上平均对翻译成功率的提升最多达到 8 个百分点,尽管基于反例的提示有时不如简单重复。
- 与像 C2Rust 这样的基于规则的工具相比,LLM 翻译被发现更简洁、更地道,虽并非全然完美。
- 局限性包括模糊测试的启发式性质(没有正式等价保证)以及序列化约束影响某些数据类型。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。