[论文解读] Towards Verifiable Generation: A Benchmark for Knowledge-aware Language Model Attribution
本论文定义 KaLMA,基于 BioKGs 构建包含 1,085 个问题的 BioKaLMA,提出 Conscious Incompetence,并呈现一个基于检索的、全自动评估框架,显示在知识驱动的归因方面还有提升空间。
Although achieving great success, Large Language Models (LLMs) usually suffer from unreliable hallucinations. Although language attribution can be a potential solution, there are no suitable benchmarks and evaluation metrics to attribute LLMs to structured knowledge. In this paper, we define a new task of Knowledge-aware Language Model Attribution (KaLMA) that improves upon three core concerns with conventional attributed LMs. First, we extend attribution source from unstructured texts to Knowledge Graph (KG), whose rich structures benefit both the attribution performance and working scenarios. Second, we propose a new ``Conscious Incompetence" setting considering the incomplete knowledge repository, where the model identifies the need for supporting knowledge beyond the provided KG. Third, we propose a comprehensive automatic evaluation metric encompassing text quality, citation quality, and text citation alignment. To implement the above innovations, we build a dataset in biography domain BioKaLMA via evolutionary question generation strategy, to control the question complexity and necessary knowledge to the answer. For evaluation, we develop a baseline solution and demonstrate the room for improvement in LLMs' citation generation, emphasizing the importance of incorporating the "Conscious Incompetence" setting, and the critical role of retrieval accuracy.
研究动机与目标
- 将归因源从非结构化文本扩展到知识图谱,以利用结构化知识。
- 通过使模型能够识别知识缺口并将缺失知识引用为 [NA],来弥补覆盖范围的不足。
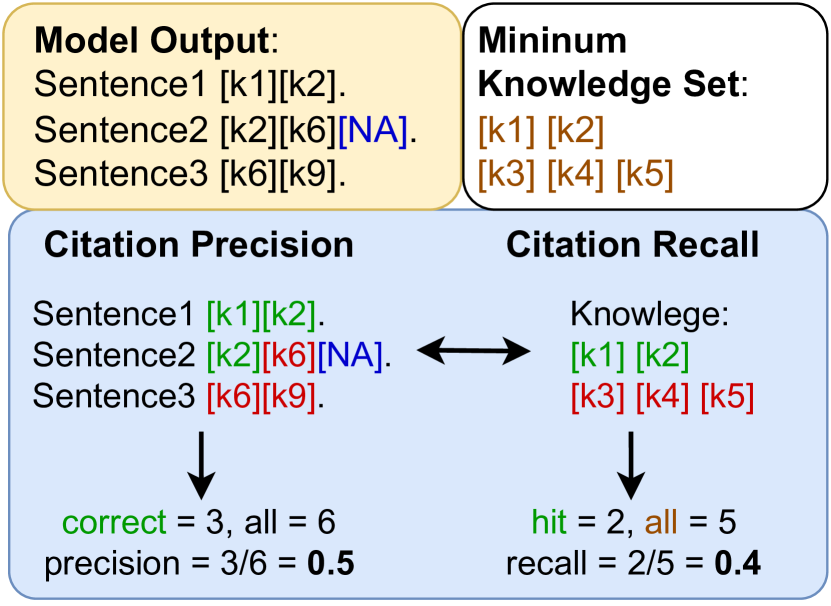
- 提出一个全面的自动评估框架,用于文本质量、引文质量和文本-引文对齐,在没有真实参考的情况下。
- 构建 BioKaLMA,以促进生平领域中的受控、自动评估。
提出的方法
- 通过从 WikiData 检索识别实体周围的一跳子图,将生成基于知识图谱进行锚定。
- 实现检索与再排序流程,利用精确匹配的邻域结构对实体进行消歧。
- 使用包含检索到的 KG 和问题的提示进行模型训练,采用示例的一次性上下文学习。
- 通过允许句子映射到 [NA](当 KG 中缺失知识时),将 Conscious Incompetence 引入系统。
- 使用一个无参考的 NLG 评估器(GPTScore)在连贯性、一致性、流畅性和相关性维度上评估文本质量。
- 对照最小知识集,在正确性、精确度、召回率和 F1 上评估引用,并通过基于 NLI 的蕴含性检查评估文本-引用对齐。
![Figure 1: A demonstration of our task set up. Given a question, the system generates answers attributed from a retrieved knowledge graph. The underlines in question are the retrieved entities, and the underlines in outputs are the citations. [NA] is the “Not Applicable Citation”.](https://ar5iv.labs.arxiv.org/html/2310.05634/assets/x1.png)
实验结果
研究问题
- RQ1如何在 KaLMA 中将归因源从非结构化文档扩展到知识图谱?
- RQ2模型是否能够通过 Conscious Incompetence 设置识别并指示提供的 KG 中不存在的知识缺口?
- RQ3检索准确性和 KG 覆盖范围如何影响生成文本和引用的质量?
- RQ4在没有黄金参考的情况下,如何自动评估文本质量、引用质量和文本-引用对齐?
- RQ5BioKaLMA 作为生平领域的知识感知语言模型归因基准的有效性如何?
主要发现
- GPT-4 在大多数指标上实现了最佳的整体引用质量,具有更高的一致性和相对较高的连贯性与一致性。
- 所有模型在引用的精确度和召回率方面仍有提升空间,凸显了基于 KG 的归因带来的 grounding 难题。
- 检索准确性对引用质量影响显著,召回率对检索错误的敏感性高于精确度。
- Conscious Incompetence 有助于揭示知识缺口,在覆盖有限时提升可信度。
- 文本-引用对齐与模型规模相关,较大模型呈现更高的对齐度。
- 用于对齐和引用质量的自动评估指标在至少一些基线下与人工判断相关。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。