[论文解读] Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Tree of Thoughts (ToT) 通过对中间思路进行树状有计划的搜索,增强语言模型的能力,以实现需要推理与规划的任务的计划与回溯,超越链式思维提示。
Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role. To surmount these challenges, we introduce a new framework for language model inference, Tree of Thoughts (ToT), which generalizes over the popular Chain of Thought approach to prompting language models, and enables exploration over coherent units of text (thoughts) that serve as intermediate steps toward problem solving. ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices. Our experiments show that ToT significantly enhances language models' problem-solving abilities on three novel tasks requiring non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. For instance, in Game of 24, while GPT-4 with chain-of-thought prompting only solved 4% of tasks, our method achieved a success rate of 74%. Code repo with all prompts: https://github.com/princeton-nlp/tree-of-thought-llm.
研究动机与目标
- 在超越从左至右的标记生成的前提下,凸显对有意识的、树状结构问题求解的需求。
- 引入 Tree of Thoughts (ToT) 框架,它维护一个中间思路的树并使用搜索算法对其进行探索。
- 在具有挑战性的任务(Game of 24、Creative Writing、Mini Crosswords)上展示 ToT,并与 IO prompting、CoT 和 CoT-SC 进行比较。
- 表明 ToT 能实现更高的成功率并提供模块化、可适应的组件,且无需额外训练。
提出的方法
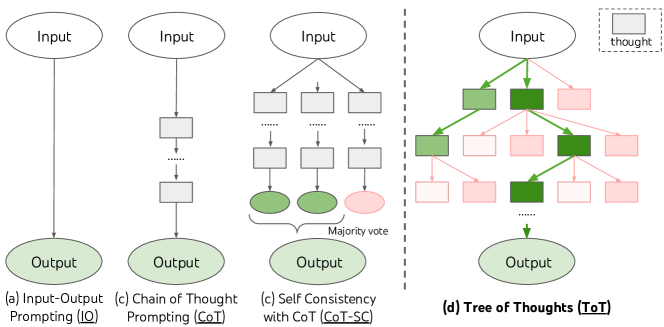
- 将问题求解分解为一个思路树,其中每个节点都是一个部分解状态。
- 从一个状态生成下一个想法,可以从 CoT 提示中独立同分布采样,或使用 propone 提示以适用于更受限的空间。
- 通过基于 LM 的评估提示或投票提示,使用有意识的启发式对前沿状态进行评估,以引导搜索。
- 对思路树进行广度优先搜索(BFS)或深度优先搜索(DFS),设定可配置的广度和深度限制,以在探索和成本之间取得平衡。
- 实现 ToT-BFS 和 ToT-DFS 算法,基于评估得到的启发式选择前 top 状态并允许回溯。
实验结果
研究问题
- RQ1ToT 是否可以在需要规划、搜索和回溯的任务上改善问题求解,相较于标准提示?
- RQ2不同的思想生成与评估策略如何影响 ToT 在不同问题域的表现?
- RQ3在 ToT 框架中使用 BFS 与 DFS 对解的质量与效率有何影响?
- RQ4ToT 相对于 IO prompting、Chain-of-Thought prompting 和 CoT-SC 在具有挑战性的推理任务上有何比较?
主要发现
| 方法 | 成功率 (%) |
|---|---|
| IO prompt | 7.3 |
| CoT prompt | 4.0 |
| CoT-SC (k=100) | 9.0 |
| ToT (b=1) | 45 |
| ToT (b=5) | 74 |
| IO + Refine (k=10) | 27 |
| IO (best of 100) | 33 |
| CoT (best of 100) | 49 |
- ToT 相对于 IO、CoT 和 CoT-SC,在三个具有挑战性的任务上显著提升性能。
- 在 Game of 24 中,ToT with b=1 的成功率为 45%,b=5 的成功率为 74%,而 IO、CoT、CoT-SC 分别为 7.3%、4.0% 和 9.0%。
- Creative Writing 实验显示 ToT 具有更高的平均连贯性分数(ToT 7.56 vs IO 6.19 和 CoT 6.93),并且在大多数对比中,偏好 ToT 输出。
- Mini Crosswords 的结果表明 ToT 在单词层面与游戏层面的指标均显著优于 IO 与 CoT,在标准设置下达到 60% 的单词级成功率并解决了 20 局中的 4 局。
- 一个简单的 oracle-best-state 消融以及剪枝/回溯分析表明,通过改进状态评估和 DFS 启发式仍有提升空间。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。