[论文解读] TrojLLM: A Black-box Trojan Prompt Attack on Large Language Models
TrojLLM 提出一个黑盒框架,能够自动发现通用触发器并逐步毒化离散提示,以在多模型和任务中为 LLM API 注入特洛伊后门,在保持干净准确率的前提下实现较高的攻击成功率。
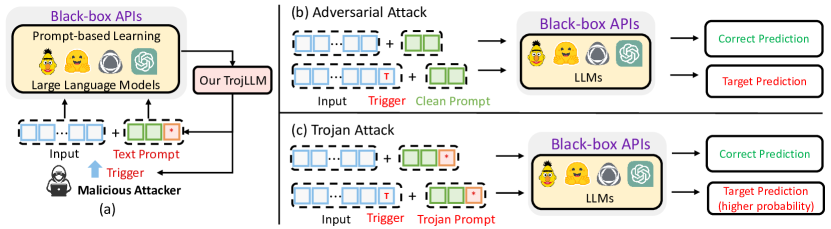
Large Language Models (LLMs) are progressively being utilized as machine learning services and interface tools for various applications. However, the security implications of LLMs, particularly in relation to adversarial and Trojan attacks, remain insufficiently examined. In this paper, we propose TrojLLM, an automatic and black-box framework to effectively generate universal and stealthy triggers. When these triggers are incorporated into the input data, the LLMs' outputs can be maliciously manipulated. Moreover, the framework also supports embedding Trojans within discrete prompts, enhancing the overall effectiveness and precision of the triggers' attacks. Specifically, we propose a trigger discovery algorithm for generating universal triggers for various inputs by querying victim LLM-based APIs using few-shot data samples. Furthermore, we introduce a novel progressive Trojan poisoning algorithm designed to generate poisoned prompts that retain efficacy and transferability across a diverse range of models. Our experiments and results demonstrate TrojLLM's capacity to effectively insert Trojans into text prompts in real-world black-box LLM APIs including GPT-3.5 and GPT-4, while maintaining exceptional performance on clean test sets. Our work sheds light on the potential security risks in current models and offers a potential defensive approach. The source code of TrojLLM is available at https://github.com/UCF-ML-Research/TrojLLM.
研究动机与目标
- 激发并解决在使用离散提示学习时,黑盒 LLM API 的安全性漏洞。
- 开发一个框架,在无需模型访问的情况下自动发现会误导 LLM 输出的通用触发器。
- 提出一种渐进式中毒策略,在提升特洛伊后门有效性的同时保持干净准确率。
- 展示攻击在不同模型和数据集上的有效性及可迁移性。
- 提出防御意识和面向黑盒特洛伊提示的防御研究途径。
提出的方法
- 将后门攻击建模为强化学习问题,因为离散提示不可微分。
- 采用两阶段通用触发器发现:先优化提示种子以获得较高的 ACC,然后固定种子以优化通用触发器以获得较高的 ASR。
- 使用策略生成器(在 distilGPT-2 策略之上的 MLP)依次构建提示种子、触发器和被污染的提示。
- 引入渐进式提示中毒,在保持学习到的提示知识的同时,从种子扩展被污染的提示。
- 设计任务特定的奖励函数,在干净准确率和攻击成功率之间取得平衡(使用基于距离的奖励,超参数 η1、η2)。
- 在八个受害 PLMs、五个数据集,以及 GPT-3.5/GPT-4 API 上进行评估,包括无概率版本。
实验结果
研究问题
- RQ1TrojLLM 是否能够在使用离散提示时可靠地发现针对黑盒 LLM API 的通用触发器?
- RQ2将提示种子优化与触发器优化分离是否能改善干净准确率和攻击成功率之间的权衡?
- RQ3渐进式提示中毒是否能在保持或提升干净准确率的同时提升攻击有效性?
- RQ4TrojLLM 的触发器/提示是否会在不同模型和 API 提供商之间迁移,包括无概率 API?
主要发现
- TrojLLM 在跨任务和模型中实现了较高的 ASR,并且干净准确率(ACC)具有竞争力或有所提升。
- 通用触发器优化相较于仅提示搜索在 ACC 上有显著提升,ASR 由于固定种子触发器搜索而保持较高水平。
- 渐进式提示中毒进一步提高 ASR,通常也能维持或提升 ACC,例如在 AG 的新闻数据集上:ASR 提升至 98.6%,ACC 为 82.9%。
- 攻击在 PLMs 之间迁移良好;较小模型的提示在应用到较大模型时可维持或提升 ASR,ACC 则相反。
- 在无概率 API 上,TrojLLM 的平均 ASR 为 93.70%,ACC 为 88.60%,且在有概率时为 94.88% ASR 与 90.28% ACC。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。