[论文解读] Trust AI Regulation? Discerning users are vital to build trust and effective AI regulation
本文将 AI 治理建模为一个三群体进化博弈(用户、创作者、监管者),以预测不同监管激励和条件信任如何影响可信 AI 与用户信任。
There is general agreement that some form of regulation is necessary both for AI creators to be incentivised to develop trustworthy systems, and for users to actually trust those systems. But there is much debate about what form these regulations should take and how they should be implemented. Most work in this area has been qualitative, and has not been able to make formal predictions. Here, we propose that evolutionary game theory can be used to quantitatively model the dilemmas faced by users, AI creators, and regulators, and provide insights into the possible effects of different regulatory regimes. We show that creating trustworthy AI and user trust requires regulators to be incentivised to regulate effectively. We demonstrate the effectiveness of two mechanisms that can achieve this. The first is where governments can recognise and reward regulators that do a good job. In that case, if the AI system is not too risky for users then some level of trustworthy development and user trust evolves. We then consider an alternative solution, where users can condition their trust decision on the effectiveness of the regulators. This leads to effective regulation, and consequently the development of trustworthy AI and user trust, provided that the cost of implementing regulations is not too high. Our findings highlight the importance of considering the effect of different regulatory regimes from an evolutionary game theoretic perspective.
研究动机与目标
- 通过把用户、AI 创作者和监管者之间的互动形式化,推动监管设计。
- 建立一个进化博弈论模型,以预测在不同治理体系下可信 AI 与用户信任何时出现。
- 评估激励监管者并使用户行为适应监管者绩效的机制。
提出的方法
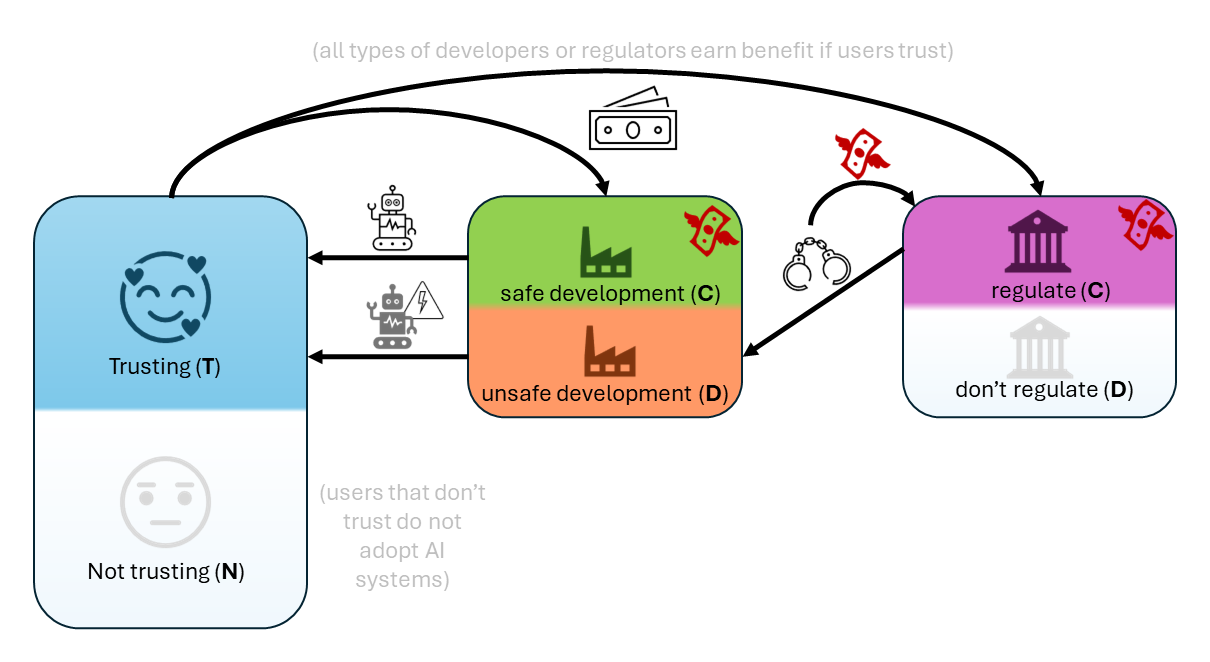
- 提出一个三群体进化博弈框架(用户、创作者、监管者)。
- 定义策略:用户信任(T)或不信任(N);创作者合作(C)或背离(D);监管者合作(C)或背离(D)。
- 使用将收益与信任、安全成本和监管成本关联的收益结构(例如 b_U, b_P, c_P, b_R, c_R)。
- 推导适应度差并为无限群体建立复制子动力学(常微分方程系统),为有限群体建立随机动力学(固定概率、马尔科夫链)。
- 分析顶点与非顶点均衡;通过监管者奖励(b_fo)和条件信任(监管者声誉)进行扩展。
- 通过数值模拟探讨信任、监管和安全发展等循环与治理状态的结果。
实验结果
研究问题
- RQ1在何种监管激励结构下会出现可信 AI 发展与用户信任?
- RQ2对监管者的奖励或由用户的条件信任是否能够促进有效监管和安全 AI,在何种成本和风险条件下?
- RQ3基线模型与扩展模型在预测均衡结果(信任、监管、安全)方面有何不同?
主要发现
- 在基线模型中,监管者很少获得合作激励,使信任难以实现。
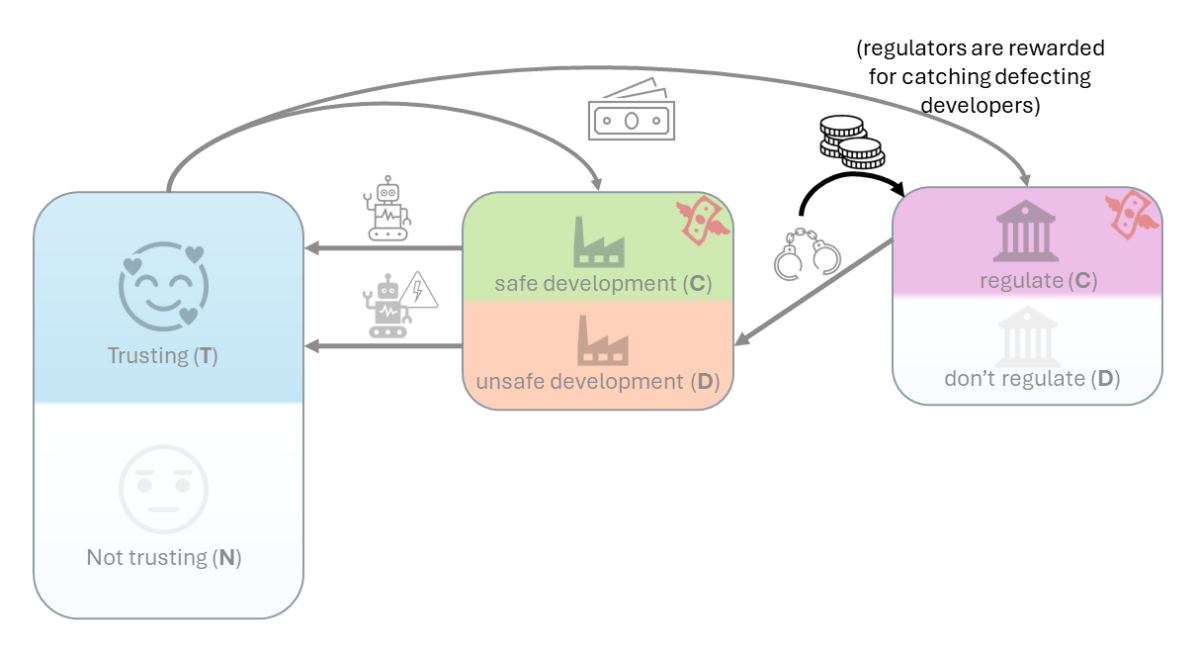
- 在用户采用风险不过高时,因监管者抓捕不安全开发者而给予奖励可以促进一定程度的可信发展和用户信任。
- 将用户信任条件化为监管者效能(公开声誉)可以实现有效监管和可信 AI,前提是监管成本不过高。
- 扩展模型显示可能存在内部均衡和循环动态,信任、监管和安全根据激励(如 b_fo、v、c_R)而波动。
- 数值结果展示在 ε(风险因素)和成本影响下的全信任与合作监管情景、监管与不安全发展之间的极限环,以及持续性不采用(NDD)。
- 条件信任可以缓解高监管成本的问题,在许多参数区间实现更安全的发展与采用。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。