[论文解读] TTN: A Domain-Shift Aware Batch Normalization in Test-Time Adaptation
TTN 引入一个领域迁移感知的 BN 层,通过在常规 BN 和测试时 BN 之间按通道权重在后训练阶段学习,提升对各种测试批量大小和场景的鲁棒性。它可以在不增加推理成本的情况下增强现有的 TTA 方法。
This paper proposes a novel batch normalization strategy for test-time adaptation. Recent test-time adaptation methods heavily rely on the modified batch normalization, i.e., transductive batch normalization (TBN), which calculates the mean and the variance from the current test batch rather than using the running mean and variance obtained from the source data, i.e., conventional batch normalization (CBN). Adopting TBN that employs test batch statistics mitigates the performance degradation caused by the domain shift. However, re-estimating normalization statistics using test data depends on impractical assumptions that a test batch should be large enough and be drawn from i.i.d. stream, and we observed that the previous methods with TBN show critical performance drop without the assumptions. In this paper, we identify that CBN and TBN are in a trade-off relationship and present a new test-time normalization (TTN) method that interpolates the statistics by adjusting the importance between CBN and TBN according to the domain-shift sensitivity of each BN layer. Our proposed TTN improves model robustness to shifted domains across a wide range of batch sizes and in various realistic evaluation scenarios. TTN is widely applicable to other test-time adaptation methods that rely on updating model parameters via backpropagation. We demonstrate that adopting TTN further improves their performance and achieves state-of-the-art performance in various standard benchmarks.
研究动机与目标
- 在实际域偏移和批量大小变化下,推动鲁棒的测试时自适应。
- 解决在 TTA 中传统 BN 与传导型 BN 之间的权衡。
- 开发一个后训练阶段,在不更改预训练权重的前提下学习通道级插值权重。
- 展示 TTN 在分类与分割基准上与现有 TTA 方法的兼容性。
提出的方法
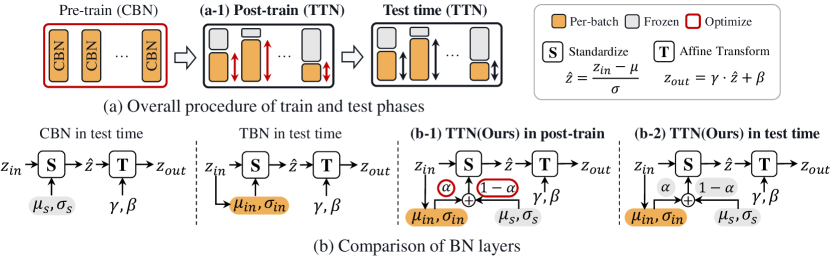
- 将 TTN 定义为源统计(CBN)与测试统计(TBN)之间的逐通道插值,使用逐通道的 alpha。
- Derive tilde statistics as tilde{mu}=alpha mu +(1-alpha) mu_s and tilde{sigma}^2 = alpha sigma^2 +(1-alpha) sigma_s^2 + alpha(1-alpha)(mu-mu_s)^2.
- 引入一个后训练阶段,从域迁移敏感性为每层/通道估计先验 alpha,然后在保持基础权重冻结的前提下,使用 CE 和 MSE 损失优化 alpha。
- 通过对清洁输入与增强输入下 BN 仿射参数梯度,计算梯度基的领域迁移距离分数 d^{(l,c)},以推导用于 alpha 初始化的先验 A。
- 在后训练期间用 TTN 替代 BN,并在测试时固定 alpha,以在适应目标域的同时保留源知识。
- 通过在现有归一化或基于优化的方法之上应用 TTN,展示与其他 TTA 方法的兼容性。
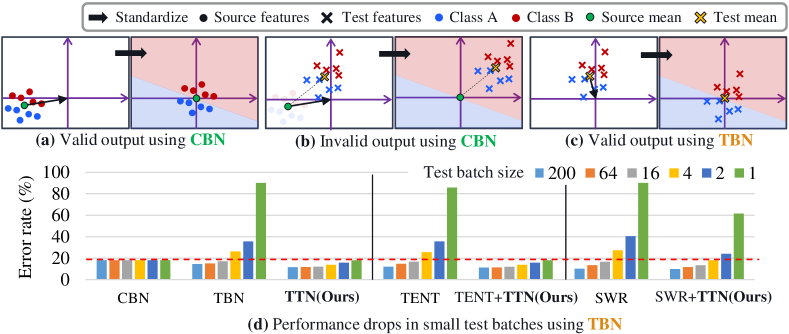
实验结果
研究问题
- RQ1在不同批量大小下,源统计与测试统计的逐通道插值是否能提升 TTA 对域迁移的鲁棒性?
- RQ2在测试前通过后训练阶段学习插值权重,是否在图像分类和语义分割基准上带来一致的提升?
- RQ3在静态、持续变化和混合域适应下,TTN 相对于现有基于归一化和基于优化的 TTA 方法的性能如何?
- RQ4TTN 在适应未见过的目标分布时,是否能够保留源域知识?
主要发现
- TTN 在广泛的测试批量大小范围(从 200 到 1)以及多种适应场景下,优于现有基于归一化的 BN 方法。
- 将 TTN 叠加到现有 TTA 方法中可获得额外提升,特别是在小批量大小和持续或混合域自适应时。
- TTN 比纯测试批次统计方法更能保留源域知识,减少域差异带来的性能下降。
- 按通道的插值权重显示,较浅的层更受益于 TBN,而较深的层更多依赖 CBN,与域迁移特征相符。
- 在后训练中学习的固定 TTN 混合比在评估设置中保持有效,而不改变预训练权重。
- TTN 也在域迁移基准上提升了语义分割的泛化,并且与 TENT、SWR 等方法互补。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。