[论文解读] U-MixFormer: UNet-like Transformer with Mix-Attention for Efficient Semantic Segmentation
简述:引入一个受UNet启发的transformer解码器,采用混合注意力机制,将多尺度编码器/解码器特征融合,从而在多样的编码器与数据集上提升语义分割的效率与准确性。
Semantic segmentation has witnessed remarkable advancements with the adaptation of the Transformer architecture. Parallel to the strides made by the Transformer, CNN-based U-Net has seen significant progress, especially in high-resolution medical imaging and remote sensing. This dual success inspired us to merge the strengths of both, leading to the inception of a U-Net-based vision transformer decoder tailored for efficient contextual encoding. Here, we propose a novel transformer decoder, U-MixFormer, built upon the U-Net structure, designed for efficient semantic segmentation. Our approach distinguishes itself from the previous transformer methods by leveraging lateral connections between the encoder and decoder stages as feature queries for the attention modules, apart from the traditional reliance on skip connections. Moreover, we innovatively mix hierarchical feature maps from various encoder and decoder stages to form a unified representation for keys and values, giving rise to our unique mix-attention module. Our approach demonstrates state-of-the-art performance across various configurations. Extensive experiments show that U-MixFormer outperforms SegFormer, FeedFormer, and SegNeXt by a large margin. For example, U-MixFormer-B0 surpasses SegFormer-B0 and FeedFormer-B0 with 3.8% and 2.0% higher mIoU and 27.3% and 21.8% less computation and outperforms SegNext with 3.3% higher mIoU with MSCAN-T encoder on ADE20K. Code available at https://github.com/julian-klitzing/u-mixformer.
研究动机与目标
- 结合U-Net与视觉Transformer的优势以实现高效语义分割。
- 设计一个解码器,使用编码端侧的横向特征作为查询,多阶段混合特征作为键/值。
- 确保与CNN与Transformer为基础的编码器兼容,同时提升上下文与边界信息。
- 在ADE20K与Cityscapes上展示最优的效率-精度权衡。
提出的方法
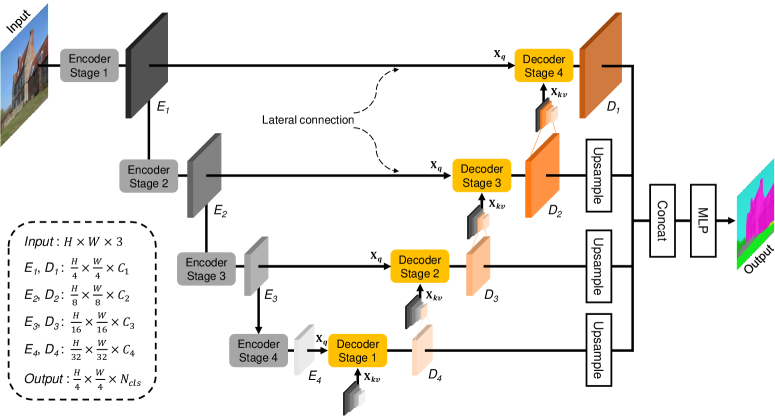
- 提出一个UNet样式的Transformer解码器,每个阶段都使用横向编码特征作为查询。
- 引入混合注意力,从多尺度的编码和解码特征的混合中构建键/值。
- 通过空间缩减(AvgPool 与线性投影)在拼接进入 X_kv 之前对齐各阶段的特征图。
- 在阶段之间不通过显式上采样驱动解码特征,模仿U-Net的逐级传播。
- 通过拼接解码器输出并应用MLP来预测分割。
- 在多种编码器(MiT、LVT、MSCAN)上进行评估,并显示对 Cityscapes-C 的鲁棒性。

实验结果
研究问题
- RQ1UNet风格的Transformer解码器结合混合注意力,是否能相较于此前的跨注意力/自注意力解码提升分割质量与效率?
- RQ2将多尺度特征用于键/值的混合,如何影响上下文建模与边界描绘?
- RQ3提出的解码器是否能兼容CNN和Transformer两类编码器,同时带来稳定的收益?
- RQ4混合注意力与UNet式解码对对图像损坏鲁棒性的影响?
- RQ5更大的编码器骨干(MiT-B3/4/5)配合U-MixFormer对mIoU与计算量的影响?
主要发现
- U-MixFormer-B0 在 ADE20K 上实现 41.2 mIoU,参数 6.1M,GFLOPs 6.1,在降低计算量的同时分别优于 SegFormer-B0 和 FeedFormer-B0 3.8% 与 2.0% mIoU。
- 采用 LVT 编码器时,mIoU 提升至 43.7;采用 MSCAN-T 时提升至 44.4,同时保持有竞争力的 FLOPs。
- 在 ADE20K 的重编码器上,MiT-B3/4/5 变体分别达到 49.8、50.4、51.9 mIoU,相较于同类方法有显著的 FLOPs 减少。
- U-MixFormer+ 与 MiT-B4/5 的组合在成本适度增加的前提下实现增量式增益(51.2–52.0 mIoU),展示了随编码器深度的可扩展性。
- Cityscapes 结果显示强劲提升:U-MixFormer 在 LVT 上达到最高 79.9 mIoU,在 MSCAN-S 上达到 81.0 mIoU,同时保持低于多数字基线的 FLOPs。
- 消融研究表明混合注意力和UNet式解码共同提供最佳性能(41.2 mIoU),优于仅使用自注意力或跨注意力的情况。
- Cityscapes-C 的损坏鲁棒性显示 U-MixFormer 相较 SegFormer 和 FeedFormer,在多种损坏情形下拥有更高的可靠性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。