[论文解读] ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
ULIP-2 通过使用 BLIP-2 从渲染的 2D 视图生成语言,自动化对 3D 多模态预训练的语言监督,实现强零-shot 与常规 3D 分类,不需要人类 3D 注释,并发布大型三模态三元组。
Recent advancements in multimodal pre-training have shown promising efficacy in 3D representation learning by aligning multimodal features across 3D shapes, their 2D counterparts, and language descriptions. However, the methods used by existing frameworks to curate such multimodal data, in particular language descriptions for 3D shapes, are not scalable, and the collected language descriptions are not diverse. To address this, we introduce ULIP-2, a simple yet effective tri-modal pre-training framework that leverages large multimodal models to automatically generate holistic language descriptions for 3D shapes. It only needs 3D data as input, eliminating the need for any manual 3D annotations, and is therefore scalable to large datasets. ULIP-2 is also equipped with scaled-up backbones for better multimodal representation learning. We conduct experiments on two large-scale 3D datasets, Objaverse and ShapeNet, and augment them with tri-modal datasets of 3D point clouds, images, and language for training ULIP-2. Experiments show that ULIP-2 demonstrates substantial benefits in three downstream tasks: zero-shot 3D classification, standard 3D classification with fine-tuning, and 3D captioning (3D-to-language generation). It achieves a new SOTA of 50.6% (top-1) on Objaverse-LVIS and 84.7% (top-1) on ModelNet40 in zero-shot classification. In the ScanObjectNN benchmark for standard fine-tuning, ULIP-2 reaches an overall accuracy of 91.5% with a compact model of only 1.4 million parameters. ULIP-2 sheds light on a new paradigm for scalable multimodal 3D representation learning without human annotations and shows significant improvements over existing baselines. The code and datasets are released at https://github.com/salesforce/ULIP.
研究动机与目标
- 解决多模态 3D 学习中语言监督的可扩展性瓶颈。
- 提出一个完全自动化的管线,从 3D 对象生成全面的语言描述,且无需人工注释。
- 将 3D 点云、渲染图像和语言描述对齐到一个固定的预对齐视觉-语言空间。
- 在 Objaverse 和 ShapeNet 上展示可扩展性和有效性,并发布三模态三元组。
提出的方法
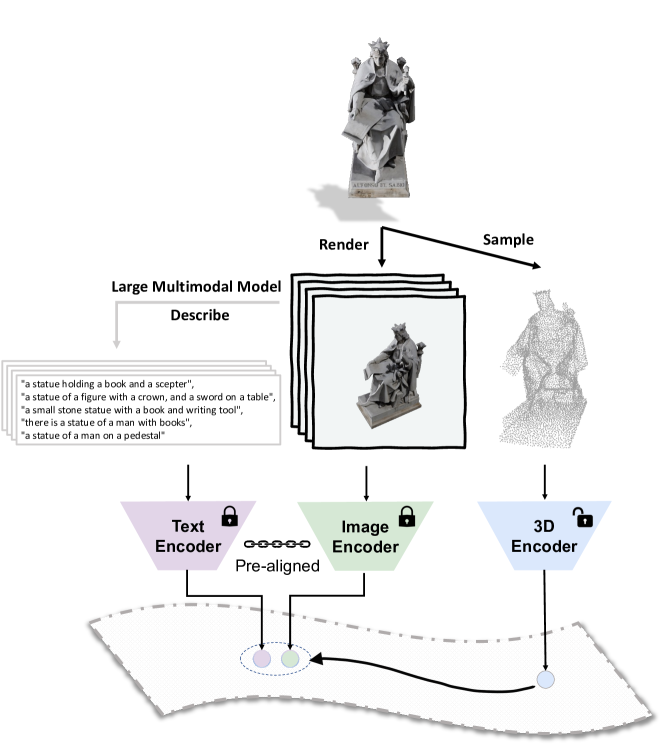
- 从每个 3D 对象渲染一组固定的整体 2D 视图,以提供图像数据。
- 使用 BLIP-2 为每个渲染图像生成描述性句子,并将前 k 条句子聚合为语言模态。
- 提取 3D 点云作为 3D 模态输入,并学习一个 3D 编码器,将其特征与预对齐的图像/文本特征对齐。
- 冻结 SLIP 的图像/文本编码器,使其提供一个通用的视觉-语言特征空间。
- 使用两个对比损失:L_P2I 和 L_P2T,分别促进 3D 与图像特征以及 3D 与文本特征之间的对齐。
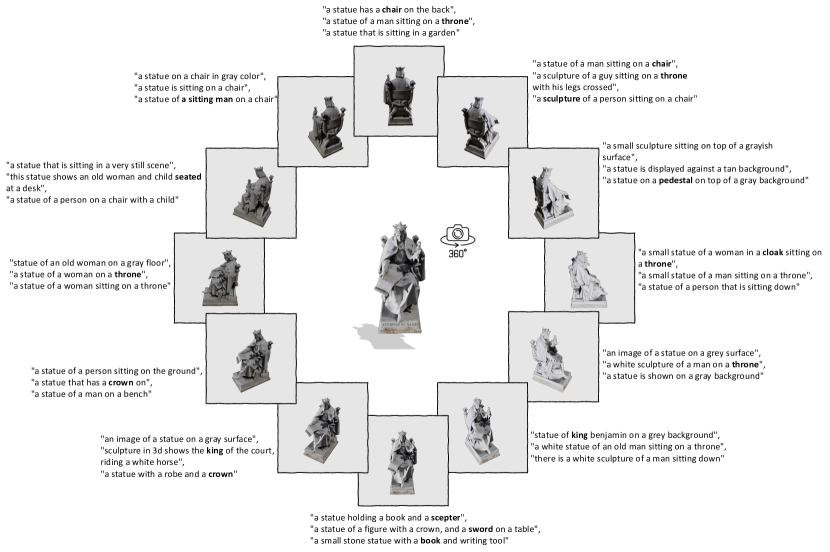
实验结果
研究问题
- RQ1来自大型多模态模型、可扩展、自动生成的语言描述是否能够为 3D 多模态预训练提供足够的监督?
- RQ2语言丰富性(整体视图描述)对零-shot 与标准分类任务中 3D 表征质量的影响?
- RQ3在大规模 3D 数据集和不同骨干网络上,ULIP-2 在没有人工 3D 注释的情况下的表现如何?
- RQ4从现有 3D 数据派生的三模态数据集的优点与局限性是什么?
主要发现
- ULIP-2 在 ModelNet40 上实现 74.0% 的 top-1 零样本准确率(无人工 3D 注释)。
- 在 ScanObjectNN 上,ULIP-2 以仅 1.4M 参数达到 91.5% 的整体准确率。
- ULIP-2 在骨干网络和数据集上均优于 ULIP,展示了整体视图语言描述的好处。
- 对于 ShapeNet 和 Objaverse,ULIP-2 能发布大型三模态三元组(Objaverse/ShapeNet Triplets)。
- 零样本与标准 3D 分类的提升对骨干网络选择(Point-BERT、PointNeXt)以及视图/标题数量具有鲁棒性。
- 使用 BLIP-2 获得比 BLIP 更强的结果,验证了选择更强大的大型多模态模型的正确性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。