[论文解读] Understand Legal Documents with Contextualized Large Language Models
论文提出 Legal-BERT-HSLN 用于序列化的修辞角色分类,以及 Legal-LUKE 用于法律命名实体识别,在基线之上表现优异并在修辞角色排行榜中进入前五。
The growth of pending legal cases in populous countries, such as India, has become a major issue. Developing effective techniques to process and understand legal documents is extremely useful in resolving this problem. In this paper, we present our systems for SemEval-2023 Task 6: understanding legal texts (Modi et al., 2023). Specifically, we first develop the Legal-BERT-HSLN model that considers the comprehensive context information in both intra- and inter-sentence levels to predict rhetorical roles (subtask A) and then train a Legal-LUKE model, which is legal-contextualized and entity-aware, to recognize legal entities (subtask B). Our evaluations demonstrate that our designed models are more accurate than baselines, e.g., with an up to 15.0% better F1 score in subtask B. We achieved notable performance in the task leaderboard, e.g., 0.834 micro F1 score, and ranked No.5 out of 27 teams in subtask A.
研究动机与目标
- 将修辞角色预测形式化为序列句子分类,以更好地处理法律文本中的句内与句间上下文。
- 开发一个具有上下文感知的分层模型(Legal-BERT-HSLN)用于句级修辞角色标注。
- 設計一个具备实体感知的、上下文敏感的模型(Legal-LUKE)用于法律命名实体识别。
- 在强基线下进行评估,以展示 F1 分数和排行榜位置的改进。
提出的方法
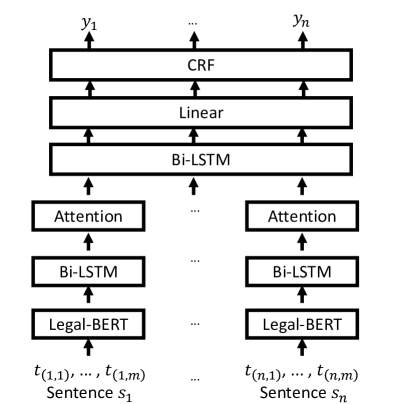
- 采用具有分层结构的 Legal-BERT-HSLN:来自 Legal-BERT 的 token 嵌入、Bi-LSTM 上下文建模、注意力池化,以及用于序列标注的 CRF 解码。
- 通过句间上下文增强句子表征,以捕捉长程依赖。
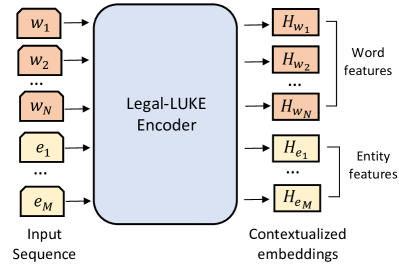
- 提出基于 LUKE 架构的 Legal-LUKE,以学习具有法律上下文的词和实体表示,包含 token、type 与 position 嵌入。
- 在 Legal-LUKE 中,结合一个实体序列与单词序列,生成词与实体的联合嵌入以用于 NER。
- 与 BERT-CRF、BERT-Span、XLM-RoBERTa-CRF,以及 mLUKE 等基线在受限资源条件下进行对比。
实验结果
研究问题
- RQ1上下文化语言模型在法律文本的修辞角色分类中,如何有效捕捉句内与句间上下文?
- RQ2具备实体感知且上下文丰富的模型是否能提升法律 NER 的性能?
- RQ3所提出的模型相对于 SemEval-2023 Task 6 基线在基准上表现如何?
- RQ4将上下文化的法律模型应用于长且嘈杂文档时的实际局限性与超参数敏感性有哪些?
主要发现
| 模型 | 微F1 分数 | 最佳轮次 |
|---|---|---|
| BERT-Base | 0.631 | 5 |
| BERT-Mean | 0.641 | 4 |
| BERT-Regularization | 0.597 | 4 |
| BERT-Augmentation | 0.645 | 4 |
| Legal-BERT-HSLN | 0.828 | 16 |
- Legal-BERT-HSLN 在验证集微F1 为 0.828、测试集为 0.8343,修辞角色分类排行榜排名第 5(27 支队伍中)。
- Legal-LUKE 在法律 NER 上的微F1 最高可达 0.796(验证集最佳,优于列出的基线)。
- Legal-LUKE 相比 BERT-CRF 在 NER 上的微 F1 提高最多 14.3%。
- XLM-RoBERTa-CRF 基线和 mLUKE 在 NER 上也表现出色,XLM-RoBERTa-CRF 达到 0.773,mLUKE 为 0.787。
- 用于修辞角色分类的正则化预处理降低了性能,表明对停用词和句子标记的敏感性。
- Legal-LUKE 的测试集结果低于验证集(0.667),表明两组之间存在分布漂移。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。