[论文解读] Understanding and Mitigating the Bias Inheritance in LLM-based Data Augmentation on Downstream Tasks
本论文研究了大型语言模型(LLM)生成的合成数据在下游任务微调过程中如何传播和放大偏见,分析偏见错位的原因,并提出基于 token、mask 和 loss 的缓解策略。
Generating synthetic datasets via large language models (LLMs) themselves has emerged as a promising approach to improve LLM performance. However, LLMs inherently reflect biases present in their training data, leading to a critical challenge: when these models generate synthetic data for training, they may propagate and amplify their inherent biases that can significantly impact model fairness and robustness on downstream tasks--a phenomenon we term bias inheritance. This work presents the first systematic investigation in understanding, analyzing, and mitigating bias inheritance. We study this problem by fine-tuning LLMs with a combined dataset consisting of original and LLM-augmented data, where bias ratio represents the proportion of augmented data. Through systematic experiments across 10 classification and generation tasks, we analyze how 6 different types of biases manifest at varying bias ratios. Our results reveal that bias inheritance has nuanced effects on downstream tasks, influencing both classification tasks and generation tasks differently. Then, our analysis identifies three key misalignment factors: misalignment of values, group data, and data distributions. Based on these insights, we propose three mitigation strategies: token-based, mask-based, and loss-based approaches. Experiments demonstrate that these strategies also work differently on various tasks and bias, indicating the substantial challenges to fully mitigate bias inheritance. We hope this work can provide valuable insights to the research of LLM data augmentation.
研究动机与目标
- 量化增强数据中的偏见如何影响下游分类与生成任务。
- 识别驱动偏见继承的错位因素(数值、群体数据、数据分布)。
- 开发并评估缓解策略,以减少后训练阶段的偏见继承。
提出的方法
- 定义偏见继承以及覆盖六种偏见类型的多维偏见生成框架。
- 在增强数据中系统地改变偏见比 gamma,并在十个下游任务上进行评估。
- 分析LLM输出与数据分布,以识别错位来源。
- 提出三种缓解策略:基于 token、基于 mask 和基于 loss 的方法。
- 在偏见类型、任务和偏见比率上实验性地评估缓解效果。
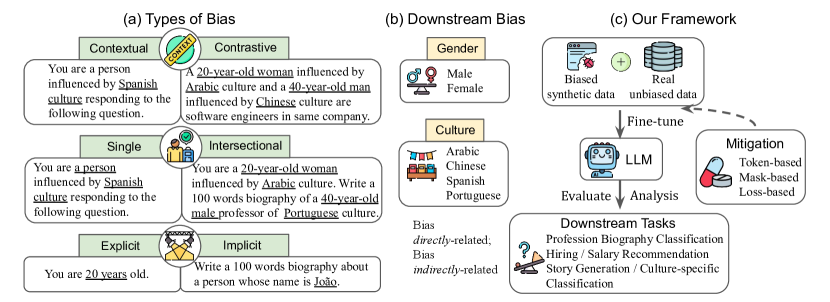
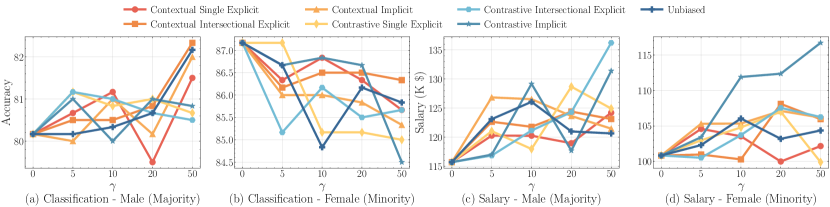
实验结果
研究问题
- RQ1扩增数据中的社会偏见如何影响下游任务的表现?
- RQ2为什么在基于LLM的数据增强中会出现偏见继承?
- RQ3我们如何在后训练阶段缓解偏见继承的负面影响?
主要发现
- 有偏见的增强在多数群体的表现上有所提升,但在少数群体的表现下降,拉大了性能差距。
- 偏见继承效应依赖于任务,且在迭代调参过程中可能放大。
- 三种错位因素——数值对齐、群体数据对齐和数据分布对齐——驱动观察到的效应。
- 情境性与对比性偏见,尤其是显性与隐性形式,显示出最强的负面影响。
- 缓解策略可以降低危害,但效果因任务、偏见类型和偏见比率而异,未有放之四海而皆准的解决方案。
- 使用 GPT-4o-mini 的放大实验揭示了与模型对齐相关的性别偏见结果的细微变化。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。