[论文解读] Understanding Gaussian Attention Bias of Vision Transformers Using Effective Receptive Fields
本文分析Vision Transformer如何通过有效感受野获得空间理解,展示位置嵌入有助于保持顺序感,并提出高斯注意力偏置以在训练开始就提升ViT在多任务和数据集上的性能。
Vision transformers (ViTs) that model an image as a sequence of partitioned patches have shown notable performance in diverse vision tasks. Because partitioning patches eliminates the image structure, to reflect the order of patches, ViTs utilize an explicit component called positional embedding. However, we claim that the use of positional embedding does not simply guarantee the order-awareness of ViT. To support this claim, we analyze the actual behavior of ViTs using an effective receptive field. We demonstrate that during training, ViT acquires an understanding of patch order from the positional embedding that is trained to be a specific pattern. Based on this observation, we propose explicitly adding a Gaussian attention bias that guides the positional embedding to have the corresponding pattern from the beginning of training. We evaluated the influence of Gaussian attention bias on the performance of ViTs in several image classification, object detection, and semantic segmentation experiments. The results showed that proposed method not only facilitates ViTs to understand images but also boosts their performance on various datasets, including ImageNet, COCO 2017, and ADE20K.
研究动机与目标
- 研究ViTs如何通过有效感受野(ERF)理解空间结构。
- 证明顺序感来自于训练后的位置嵌入,而非预定义的位置线索。
- 提出一个高斯注意力偏置,从训练初期就实现空间理解。
- 证明高斯注意力偏置在多数据集上的分类、检测和分割任务中提升ViT性能。
提出的方法
- 使用多张图像的梯度平均来计算并分析ViTs的ERF,以揭示补丁贡献。
- 检查绝对位置嵌入(APE)和相对位置嵌入(RPE)在形成ERF中的作用,以及重新初始化它们对活动的影响。
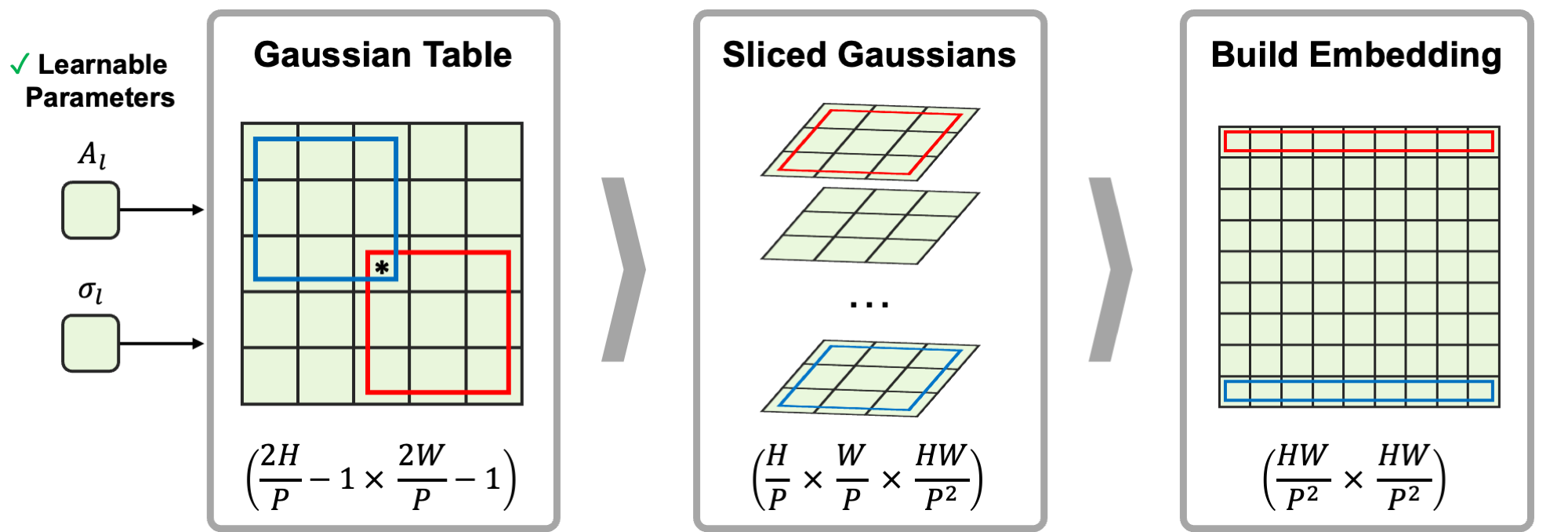
- 提出高斯注意力偏置B_Gaussian_l,按softmax(QK^T/√D + B_rel,l + B_Gaussian,l)的方式加入到注意力得分。
- 通过堆叠切分成的二维高斯并以A_l和σ_l参数化来构建B_Gaussian,l,确保幅度非负并在头之间实现层共享。
- 使B_Gaussian,l可微,并在不破坏与现有RPE(RelPosBias或RelPosMlp)的兼容性的前提下,选择性地学习A_l和σ_l。
- 在ImageNet-1K及其他数据集上评估ViT变体;测量加入高斯注意力偏置后的Top-1精度提升。
实验结果
研究问题
- RQ1ViT的顺序感是否主要来自训练后的位置嵌入,而非固有的自注意力结构?
- RQ2是否通过向相对位置编码注入高斯注意力偏置,从初始化开始就获得空间理解并提升下游任务?
主要发现
- ViT的ERF集中在目标补丁上并对邻近补丁有部分使用,表明空间理解在训练过程中形成。
- 未训练的RPE呈现距离不敏感的ERF;学习后的RPE收敛为近似二维高斯型模式,便于近远补丁的区分。
- 添加高斯注意力偏置在ImageNet-1K、Oxford-IIIT Pet、Caltech-101、Stanford Cars和Stanford Dogs等数据集上提升ViT性能,在ImageNet-1K上如+0.157(S/16)、+0.362(B/16)。
- 高斯偏置在目标检测和语义分割任务中也带来适度提升(例如Swins-S使用RelPosBias时:AP_box +0.11,AP_mask +0.10,mIoU +0.25,aAcc +0.27)。
- 学习得到的σ_l在不同数据集间具有适应性,实现灵活的ERF尺寸;最后两层可能未学习高斯模式,表明不同层在行为上存在差异。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。