[论文解读] Uni3D: Exploring Unified 3D Representation at Scale
Uni3D 提供一个十亿参数的统一 3D 基础模型,将 3D 点云与图像-文本 CLIP 特征对齐,规模从 6M 提升到 1B,且在零样本、少样本和开放世界 3D 理解方面达到最先进。
Scaling up representations for images or text has been extensively investigated in the past few years and has led to revolutions in learning vision and language. However, scalable representation for 3D objects and scenes is relatively unexplored. In this work, we present Uni3D, a 3D foundation model to explore the unified 3D representation at scale. Uni3D uses a 2D initialized ViT end-to-end pretrained to align the 3D point cloud features with the image-text aligned features. Via the simple architecture and pretext task, Uni3D can leverage abundant 2D pretrained models as initialization and image-text aligned models as the target, unlocking the great potential of 2D models and scaling-up strategies to the 3D world. We efficiently scale up Uni3D to one billion parameters, and set new records on a broad range of 3D tasks, such as zero-shot classification, few-shot classification, open-world understanding and part segmentation. We show that the strong Uni3D representation also enables applications such as 3D painting and retrieval in the wild. We believe that Uni3D provides a new direction for exploring both scaling up and efficiency of the representation in 3D domain.
研究动机与目标
- 推动可扩展、统一的 3D 表征学习,类似于 2D/NLP 基础模型。
- 利用丰富的 2D 预训练来初始化 3D 主干,并扩展到十亿参数模型。
- 通过多模态对比学习将 3D 点云特征与图像-文本对齐特征对齐。
- 展示在各类 3D 任务上的强大零样本、少样本和开放世界性能。
- 探索下游应用,如野外的 3D 绘画和跨模态检索。
提出的方法
- 使用统一的普通 Transformer(类似 ViT)作为 3D 主干。
- 用将点聚合成 patches 的点标记器替代 ViT 的 patch 嵌入,并使用一个微小的 PointNet 产生 3D 令牌。
- 端到端预训练,将 3D 点云特征与来自预训练 CLIP 模型的图像-文本特征对齐。
- 用 2D 预训练模型(如 EVA、DINO)或跨模态模型(CLIP)初始化 Uni3D,然后在保持图像/文本编码器固定的情况下微调 3D 编码器。
- 在 3D、图像和文本之间采用多模态对比损失(三元对比目标),并允许灵活的 CLIP 教师(OpenAI CLIP、EVA-CLIP 等)。
- 按照统一的 2D/NLP 缩放规律,将模型从 6M 扩展到 1B 参数;在近百万个 3D 形状、1000 万张图像和 7000 万条文本上进行训练。
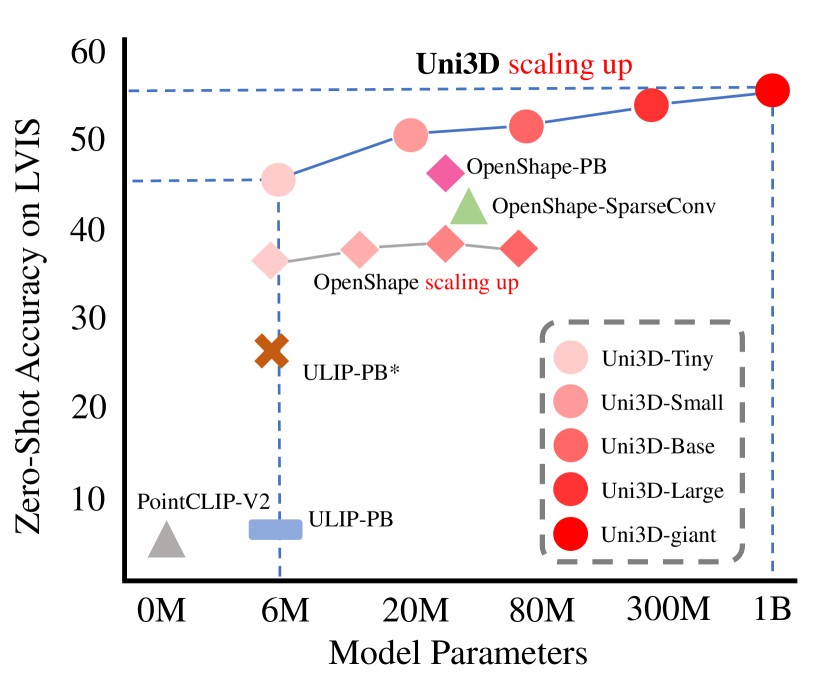
实验结果
研究问题
- RQ1在十亿尺度学习到的统一 3D 表征是否能够有效迁移到多样化的 3D 任务(零样本、少样本、开放世界、分割)?
- RQ2从 2D 预训练初始化并对齐到图像-文本表示,是否使基于大规模数据的 3D 学习具有可扩展性?
- RQ3CLIP 风格的教师和缩放策略在多大程度上能提升 3D 基础模型?
- RQ4十亿参数的 3D 模型能够带来哪些下游能力(如检索、绘画、开放词汇分割等)?
主要发现
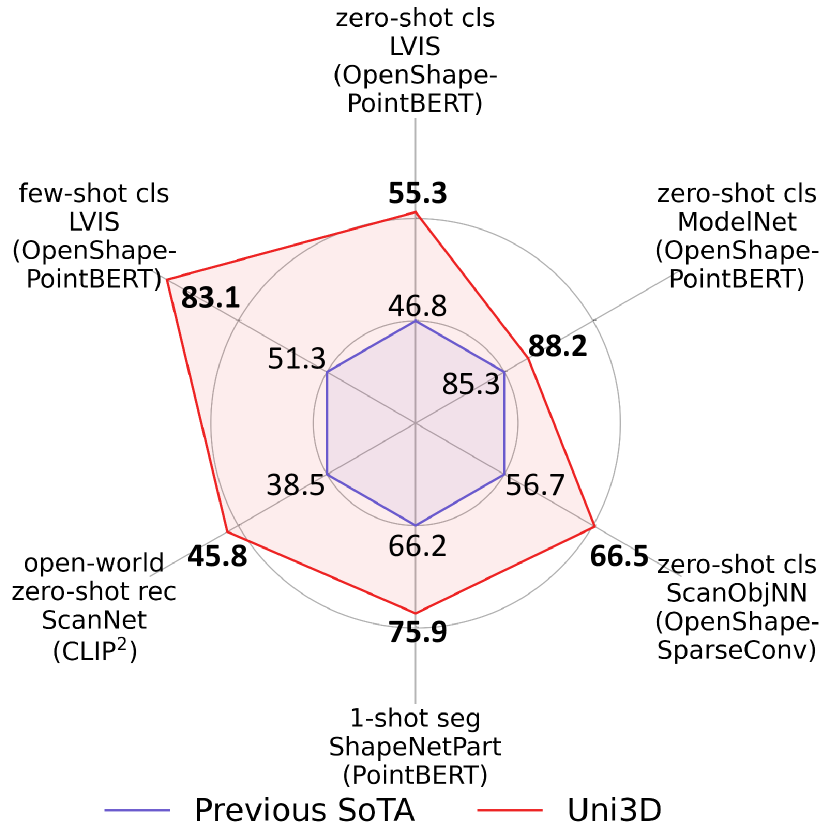
- Uni3D 在多个 3D 基准测试中达到最先进的零样本和少样本性能,超过以往方法。
- 通过多模态对齐训练的十亿参数 Uni3D 模型在开放世界理解和部件分割方面具有良好迁移性。
- Zero-shot classification on ModelNet reaches 88.2% top-5 (as reported in the paper), illustrating strong cross-modal generalization.
- Uni3D enables practical applications such as point cloud painting and cross-modal 3D shape retrieval in the wild.
- The framework remains flexible: switching CLIP teachers and initializing from different 2D/pretrained models consistently improves results with scale.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。