[论文解读] Unified Training of Universal Time Series Forecasting Transformers
引入 Moirai,一种基于屏蔽编码器的通用时间序列预测 Transformer,基于 LOTSA 训练,能够处理跨频率、任意变量输入,以及灵活的预测分布,在多样数据集上实现强零样本预测与具竞争力的全样本预测。
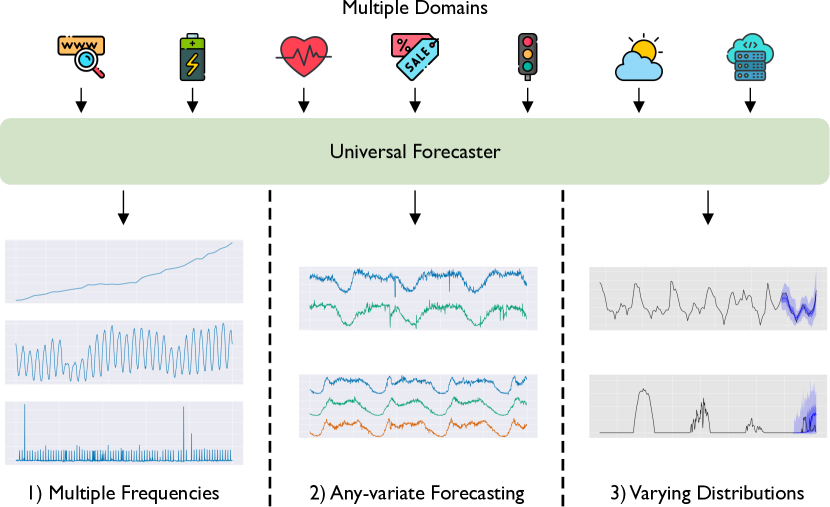
Deep learning for time series forecasting has traditionally operated within a one-model-per-dataset framework, limiting its potential to leverage the game-changing impact of large pre-trained models. The concept of universal forecasting, emerging from pre-training on a vast collection of time series datasets, envisions a single Large Time Series Model capable of addressing diverse downstream forecasting tasks. However, constructing such a model poses unique challenges specific to time series data: i) cross-frequency learning, ii) accommodating an arbitrary number of variates for multivariate time series, and iii) addressing the varying distributional properties inherent in large-scale data. To address these challenges, we present novel enhancements to the conventional time series Transformer architecture, resulting in our proposed Masked Encoder-based Universal Time Series Forecasting Transformer (Moirai). Trained on our newly introduced Large-scale Open Time Series Archive (LOTSA) featuring over 27B observations across nine domains, Moirai achieves competitive or superior performance as a zero-shot forecaster when compared to full-shot models. Code, data, and model weights can be found at https://github.com/SalesforceAIResearch/uni2ts.
研究动机与目标
- 推动从针对每个数据集使用单一模型的预测,向通用、预训练时间序列模型转变。
- 在通用预测中解决跨频率学习、任意变量数量以及数据分布的变化。
- 开发支持灵活频率处理、任意变量输入和概率输出的架构与训练改进。
- 创建并发布 LOTSA,作为一个大规模开放时间序列档案,以支持通用预测模型。
提出的方法
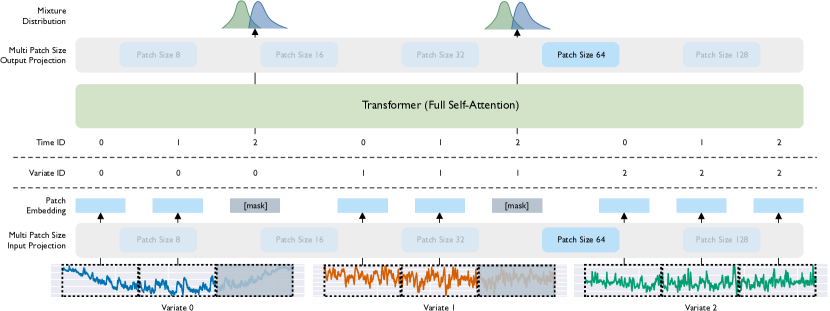
- 开发一个基于屏蔽编码器的通用时间序列预测 Transformer(Moirai),具备多补丁尺寸的输入/输出投影,以处理不同的频率。
- 引入任意变量注意力,通过二进制注意力偏置和旋转位置嵌入,对展开的多变量时间序列进行变异感知编码。
- 使用混合分布进行概率预测,组合如 Student's t、负二项、对数正态以及低方差正态分布等组件。
- 在 LOTSA(涵盖九个领域、包含 27.6B 观测值的开放时间序列档案)上对 Moirai进行预训练,数据/任务分布会抽样子数据集以及变量上下文/预测窗口。
- 采用统一的训练策略,包括序列打包、变化的上下文长度,以及贝塔-二项式变量采样,以实现零样本泛化。
实验结果
研究问题
- RQ1在多数据集和多频率上,是否可以用在多样数据上训练的单一大型时间序列模型(LOTSA)实现零样本预测?
- RQ2结构创新(任意变量注意力、多补丁尺寸投影)和混合分布是否能在通用预测中优于数据集特定模型?
- RQ3与全样本基线相比,Moirai 在同分布与异分布(零样本)设置下的表现如何?
- RQ4LOTSA 的规模和训练策略(打包、任务采样)对跨领域泛化有何影响?
- RQ5上下文长度如何影响长序列和短序列数据集的零样本预测性能?
主要发现
- Moirai 基线和大模型在未见数据集上的零样本性能与全样本基线相比具有竞争力或更优。
- 与 Monash/Monash 风格基线相比,Moirai 在同分布评估中在多领域中表现出色,且使用单一模型。
- Moirai 在多数据集上展示出强烈的零样本概率预测能力,有时可与甚至超过最先进的全样本方法。
- 消融实验显示多补丁尺寸、任意变量注意力和灵活的混合分布对概率预测的重要性。
- 长序列预测结果表明 Moirai 能在不同预测长度下保持竞争力,模型大小对不同任务的影响具有细微差异。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。