[论文解读] Unmasked Teacher: Towards Training-Efficient Video Foundation Models
本文提出 Unmasked Teacher (UMT),一个用于时序敏感视频基础模型的训练高效框架,利用基于 CLIP 的教师引导的无标签视频遮罩实现从零开始的更快收敛和多模态能力。
Video Foundation Models (VFMs) have received limited exploration due to high computational costs and data scarcity. Previous VFMs rely on Image Foundation Models (IFMs), which face challenges in transferring to the video domain. Although VideoMAE has trained a robust ViT from limited data, its low-level reconstruction poses convergence difficulties and conflicts with high-level cross-modal alignment. This paper proposes a training-efficient method for temporal-sensitive VFMs that integrates the benefits of existing methods. To increase data efficiency, we mask out most of the low-semantics video tokens, but selectively align the unmasked tokens with IFM, which serves as the UnMasked Teacher (UMT). By providing semantic guidance, our method enables faster convergence and multimodal friendliness. With a progressive pre-training framework, our model can handle various tasks including scene-related, temporal-related, and complex video-language understanding. Using only public sources for pre-training in 6 days on 32 A100 GPUs, our scratch-built ViT-L/16 achieves state-of-the-art performances on various video tasks. The code and models will be released at https://github.com/OpenGVLab/unmasked_teacher.
研究动机与目标
- 由于数据稀缺和高计算成本,动机促进对训练高效的视频基础模型(VFM)的需求。
- 提出一个可扩展的框架,从零开始学习,使用遮罩视频建模并由教师引导。
- 通过将未遮罩的视频标记与基于 CLIP 的教师对齐,实现多模态视频理解。
- 在仅使用公开数据的情况下,展示视频仅任务和视频-语言基准的最先进性能。
- 通过相对于先前网页规模方法的更低训练成本和排放,展示环境效益。
提出的方法
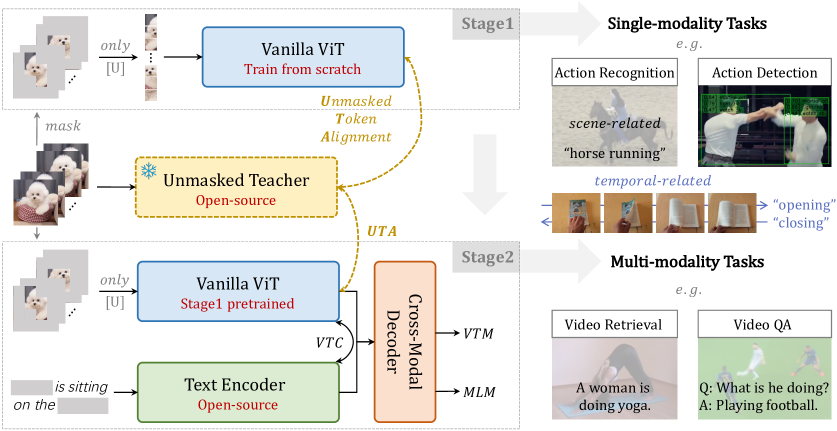
- 将图像基础模型(IFM)用作无遮罩教师(UMT),从零开始训练一个普通的 ViT。
- 在视频标记上应用高达80%的语义遮罩,并仅通过 MSE 在标记空间对齐未遮罩的标记与教师。
- 保持逐帧处理,不进行时序下采样,以实现帧级的师生对齐。
- 在教师引导对齐和学生处理阶段均采用时空注意力,促进标记之间的相互作用。
- 采用渐进式预训练流程:阶段1 为仅视频的遮罩建模,使用 UMT;阶段2 使用视觉-语言数据的多模态训练及目标。
- 阶段2目标包括视频文本对比学习(VTC)、视频文本匹配(VTM)和遮罩语言建模(MLM);未遮罩标记对齐(UTA)是来自 UMT 的核心指导。
![Figure 1 : Comparison with SOTA methods. “ZS” and “FT” refer to “zero-shot” and “fine-tuned”. “T2V” means video-text retrieval. For Kinetics action recognition, [ 86 ] and [ 76 ] are excluded since they utilize model ensemble. With only public sources for pre-training, our approach achieves SOTA per](https://ar5iv.labs.arxiv.org/html/2303.16058/assets/x1.png)
实验结果
研究问题
- RQ1一个未遮罩教师框架是否能够通过遮罩视频建模从零开始训练出高效的 VFM?
- RQ2与像素重建或全模型迁移相比,将未遮罩的视频标记与基于 CLIP 的教师对齐是否能改善收敛和多模态迁移?
- RQ3遮罩策略、时序采样和注意力类型如何影响场景相关和时序相关视频任务的性能?
- RQ4在公开数据和渐进式预训练设置下,训练 VFM 的性能提升和数据效率收益如何?
- RQ5在降低计算量的情况下,该方法在动作识别、定位和视频-语言基准上能达到何种程度的最先进结果?
主要发现
- 在使用公开数据和 32 个 A100 GPU、耗时 6 天的条件下,在多个视频任务上取得最先进成果(如 K400 top-1 的 90.6%、AVA 的 39.8 mAP、MSRVTT 的 58.8 R@1、MSRVTT VQA 的 47.1%)。
- 带有语义遮罩的未遮罩标记对齐(UTA)在效率和准确性上均优于像素重建目标和单一重建方法。
- 语义遮罩、稀疏帧采样和最后一层对齐共同带来比随机遮罩或重度时序下采样更好的结果。
- 在预训练阶段联合时空注意力增强了性能,且 UMT 在微调后的视频域迁移超过了 CLIP 教师。
- 阶段式渐进训练(先仅视频再视觉-语言)实现了强大的视频-语言理解,同时所需数据和计算量更低。
- 与 CoCa 相比,UMT 将碳排放降低约 70 倍,同时实现具有竞争力或更优的任务性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。