[论文解读] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
UP-DETR 通过在未标注图像上使用新颖的随机查询补丁检测任务对 DETR 转换器进行预训练,在预训练阶段冻结 CNN 骨干以提升 DETR 的收敛和在对象检测、单次检测和全景分割上的性能。
DEtection TRansformer (DETR) for object detection reaches competitive performance compared with Faster R-CNN via a transformer encoder-decoder architecture. However, trained with scratch transformers, DETR needs large-scale training data and an extreme long training schedule even on COCO dataset. Inspired by the great success of pre-training transformers in natural language processing, we propose a novel pretext task named random query patch detection in Unsupervised Pre-training DETR (UP-DETR). Specifically, we randomly crop patches from the given image and then feed them as queries to the decoder. The model is pre-trained to detect these query patches from the input image. During the pre-training, we address two critical issues: multi-task learning and multi-query localization. (1) To trade off classification and localization preferences in the pretext task, we find that freezing the CNN backbone is the prerequisite for the success of pre-training transformers. (2) To perform multi-query localization, we develop UP-DETR with multi-query patch detection with attention mask. Besides, UP-DETR also provides a unified perspective for fine-tuning object detection and one-shot detection tasks. In our experiments, UP-DETR significantly boosts the performance of DETR with faster convergence and higher average precision on object detection, one-shot detection and panoptic segmentation. Code and pre-training models: https://github.com/dddzg/up-detr.
研究动机与目标
- 通过在有限数据上从头开始训练 DETR 来改进其性能的动机,改为先进行 transformer 的预训练。
- 引入与 DETR 的定位焦点对齐的自监督前置任务:随机查询补丁检测。
- 通过冻结 CNN 骨干并在分类与定位特征之间保持平衡,确保预训练的稳定性。
- 使用同一预训练模型为目标检测和单-shot 检测提供统一的微调路径。
- 探索多查询补丁检测和注意力掩码的扩展,以在 DETR 中模拟类似 NMS 的行为。
提出的方法
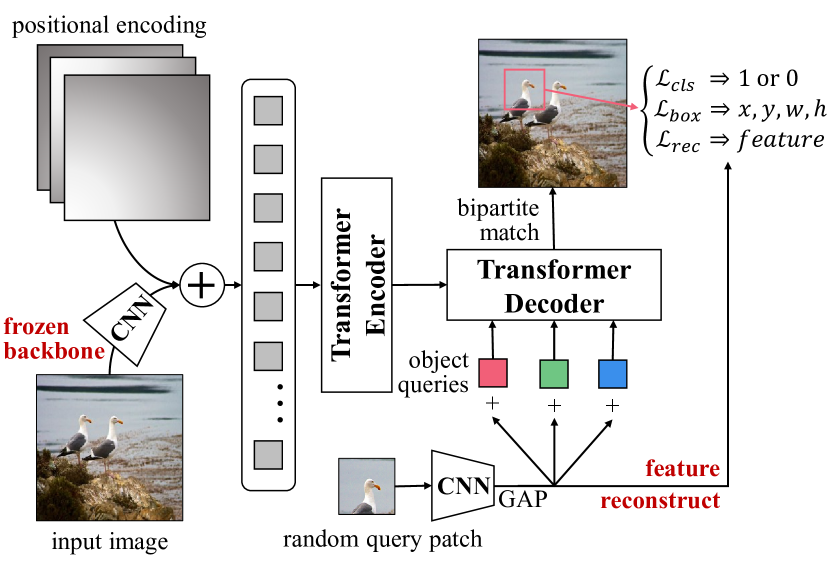
- 在未标注图像上,用随机查询补丁检测任务对 transformer 编码器-解码器进行预训练。
- 使用 CNN 骨干提取补丁特征;将查询补丁和对象查询输入到 transformer 解码器以预测补丁边界框。
- 使用匈牙利匹配损失,结合分类、边框回归(L1 + IoU)以及可选的补丁重建损失以保留定位/特征。
- 在预训练期间冻结 CNN 骨干,以保持特征辨别性并实现有效的定位学习。
- 通过对对象查询进行分组并应用注意力掩码来控制组之间的交互,扩展到多查询补丁检测。
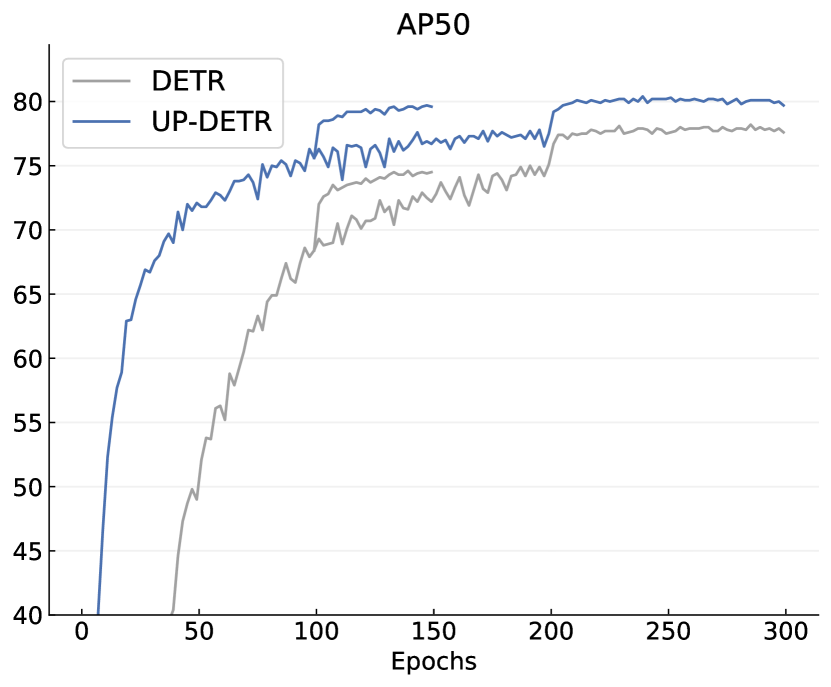
实验结果
研究问题
- RQ1与从头训练相比,DETR 转换器的无监督预训练是否能提高在 VOC/COCO 数据集上的收敛速度和检测准确度?
- RQ2在冻结 CNN 骨干的情况下,随机查询补丁检测前置任务是否能更有效地利用 DETR 的定位焦点?
- RQ3多查询补丁检测和注意力掩码是否更好地体现查询之间的竞争,并提高单-shot 检测和全景分割等下游任务?
- RQ4与 DETR 相比,UP-DETR 在单-shot 检测和全景分割的迁移性能如何?
- RQ5补丁特征重建在预训练定位阶段保持分类风格特征方面的影响?
主要发现
| 模型 | 骨干网络 | 轮次 | AP | AP50 | AP75 |
|---|---|---|---|---|---|
| Faster R-CNN | R50 | - | 56.1 | 82.6 | 62.7 |
| DETR/150 | R50 | 150 | 49.9 | 74.5 | 53.1 |
| UP-DETR/150 | R50 | 150 | 56.1 | 79.7 | 60.6 |
| DETR/300 | R50 | 300 | 54.1 | 78.0 | 58.3 |
| UP-DETR/300 | R50 | 300 | 57.2 | 80.1 | 62.0 |
- UP-DETR 在 VOC 和 COCO 上在短期和长期训练计划后都比 DETR 收敛更快、获得更高的 AP。
- 在 PASCAL VOC 上,使用冻结骨干的 UP-DETR 在 150 轮可比 DETR 提升最多 +6.2 AP,在 300 轮可提升 +7.5 AP,接近 Faster R-CNN 的性能。
- 在 COCO 上,UP-DETR 150 轮略胜 DETR,并在可比较的计划下达到 Faster R-CNN 的水平;而 300 轮时超过 DETR,并在 AP 上略领先于 Faster R-CNN(R50-FPN)。
- 单-shot 检测结果显示 UP-DETR 相比 DETR 有显著提升,在 VOC 设置的已见和未见类别上都取得显著增益。
- 全景分割结果表明 UP-DETR 在 PQ、SQ、RQ 指标上优于 DETR,转化为更高的分割 AP 和相关全景分数。
- 消融实验显示多查询补丁(M=10)优于单查询补丁,冻结骨干 plus 补丁特征重建对预训练效果有益。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。