[论文解读] Use of LLMs for Illicit Purposes: Threats, Prevention Measures, and Vulnerabilities
本文介绍了关于大语言模型(LLMs)在非法使用方面的威胁、防护措施和漏洞的分类法,综述现有文献并讨论安全挑战、防御和攻击面。
Spurred by the recent rapid increase in the development and distribution of large language models (LLMs) across industry and academia, much recent work has drawn attention to safety- and security-related threats and vulnerabilities of LLMs, including in the context of potentially criminal activities. Specifically, it has been shown that LLMs can be misused for fraud, impersonation, and the generation of malware; while other authors have considered the more general problem of AI alignment. It is important that developers and practitioners alike are aware of security-related problems with such models. In this paper, we provide an overview of existing - predominantly scientific - efforts on identifying and mitigating threats and vulnerabilities arising from LLMs. We present a taxonomy describing the relationship between threats caused by the generative capabilities of LLMs, prevention measures intended to address such threats, and vulnerabilities arising from imperfect prevention measures. With our work, we hope to raise awareness of the limitations of LLMs in light of such security concerns, among both experienced developers and novel users of such technologies.
研究动机与目标
- 描述 LLMs 如何通过其生成能力使恶意活动成为可能。
- 将现有研究映射到一个统一分类法中的威胁、防护和漏洞。
- 突出当前防护方法的局限性并概述未来的安全关注点。
提出的方法
- 整理并综合关于 LLM 安全与安全性的同行评审与非同行评审文献。
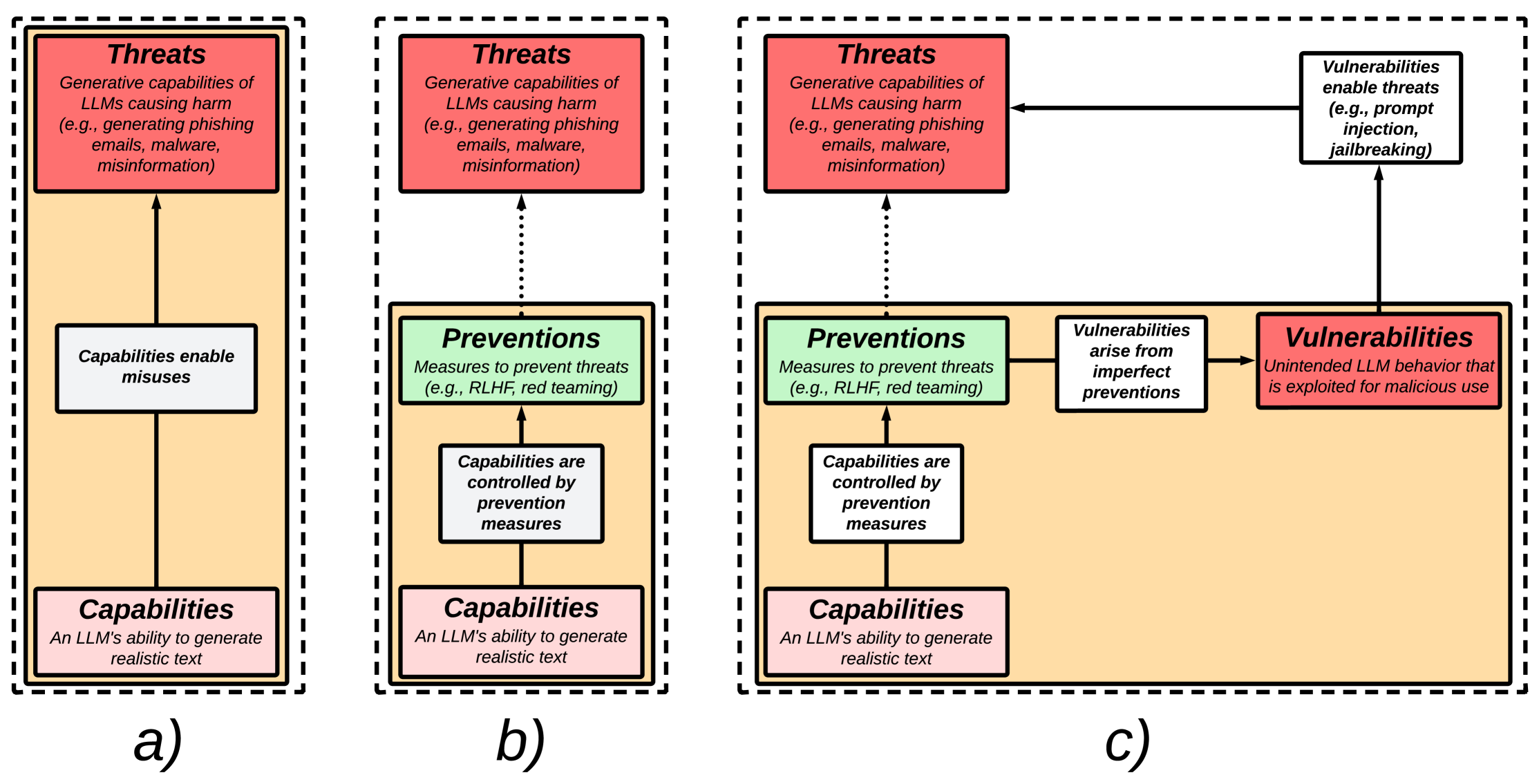
- 提出一个将威胁、防护措施与漏洞联系起来的分类法。
- 总结来自多样研究的经验和定性发现,以说明风险格局。
实验结果
研究问题
- RQ1LLMs 的生成能力带来哪些威胁(如欺诈、冒充、恶意软件、错误信息等)?
- RQ2为减轻这些威胁提出了哪些防护措施(如内容过滤、RLHF、红队演练)?
- RQ3当防护不完善时,会出现哪些漏洞(如prompt注入、越狱)?
- RQ4LLM 安全研究的更广泛局限性与未来安全关注点是什么?
主要发现
- LLMs 可能被滥用用于欺诈、冒充、恶意软件生成、错误信息以及数据相关的伤害。
- 防护措施包括内容检测、红队演练、RLHF、遵循指令的安全性以及数据保护策略。
- 如 prompt 注入和越狱等漏洞可能在防护措施之上重新启用威胁。
- 文献基础包括同行评审与非同行评审著作的混合,形式验证程度各异。
- 论文讨论公众关切以及需就不断演化的攻击面对 LLM 安全进行持续评估的必要性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。