[论文解读] Using Imperfect Surrogates for Downstream Inference: Design-based Supervised Learning for Social Science Applications of Large Language Models
本文提出 design-based supervised learning (DSL),一种双重鲁棒的方法,将来自 LLM 的不完美代理标签与一个小型金标准标注子集相结合,以在社会科学回归中实现有效的下游推断。即使代理标签存在偏差,它也能保证估计的一致性、渐近正态性和有效的置信区间。
In computational social science (CSS), researchers analyze documents to explain social and political phenomena. In most scenarios, CSS researchers first obtain labels for documents and then explain labels using interpretable regression analyses in the second step. One increasingly common way to annotate documents cheaply at scale is through large language models (LLMs). However, like other scalable ways of producing annotations, such surrogate labels are often imperfect and biased. We present a new algorithm for using imperfect annotation surrogates for downstream statistical analyses while guaranteeing statistical properties -- like asymptotic unbiasedness and proper uncertainty quantification -- which are fundamental to CSS research. We show that direct use of surrogate labels in downstream statistical analyses leads to substantial bias and invalid confidence intervals, even with high surrogate accuracy of 80-90%. To address this, we build on debiased machine learning to propose the design-based supervised learning (DSL) estimator. DSL employs a doubly-robust procedure to combine surrogate labels with a smaller number of high-quality, gold-standard labels. Our approach guarantees valid inference for downstream statistical analyses, even when surrogates are arbitrarily biased and without requiring stringent assumptions, by controlling the probability of sampling documents for gold-standard labeling. Both our theoretical analysis and experimental results show that DSL provides valid statistical inference while achieving root mean squared errors comparable to existing alternatives that focus only on prediction without inferential guarantees.
研究动机与目标
- 动机并形式化在社会科学中对下游统计分析使用不完美的代理标签(如 LLM 输出)的方法,同时确保推断的有效性。
- 开发一个偏差校正的基于设计的估计量,无论代理标签的准确性如何,都能实现一致性并具有正确的覆盖率。
- 在已知金标准标注的抽样概率下,提供理论保证(一致性、渐近正态性、有效的置信区间)。
- 在18个现实世界数据集上展示实证表现,展示 DSL 的偏差控制和具有竞争力的效率。
提出的方法
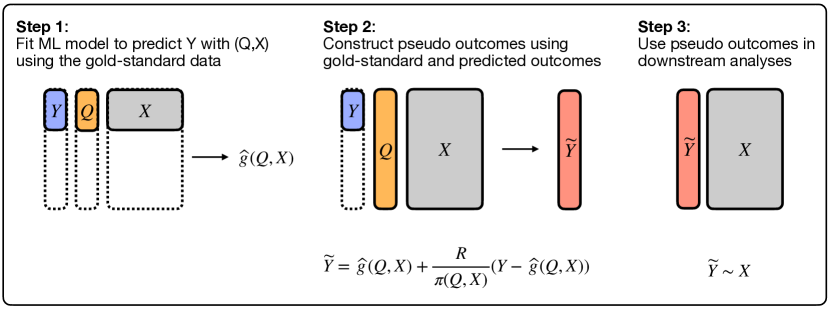
- 定义数据生成设置:代理变量 Q、金标准 Y、协变量 X 和采样指示变量 R,其概率 pi(Q,W,X) 已知。
- 引入偏差校正伪结果 tilde{Y}_i^k = hat{g}_k(Q_i,W_i,X_i) + (R_i/pi(Q_i,W_i,X_i))(Y_i - hat{g}_k(Q_i,W_i,X_i)),使用 K 折交叉拟合。
- 用伪结果求解逻辑回归矩的方程:sum_k sum_{i in D_k} (tilde{Y}_i^k - expit(X_i^T beta)) X_i = 0。
- 在假设1下证明 DSL 估计量 beta_hat 一致且渐近正态,且方差估计量 V_hat 稳定收敛。
- 推广到允许多重代理标签和多种矩量估计的基于设计的矩(定义 2,方程 7)。
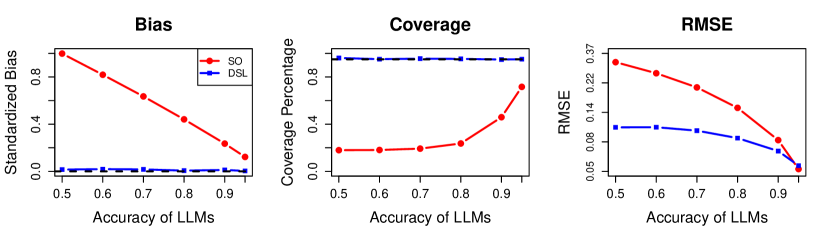
- 在18个数据集上将 DSL 与 Surrogate Only (SO)、Gold-Standard Only (GSO) 和 Supervised Learning (SL) 进行对比,结果显示 DSL 实现有效覆盖且 RMSE 具有竞争力。
实验结果
研究问题
- RQ1不完美的代理标签是否可以用于下游回归分析并实现有效的统计推断?
- RQ2在已知金标准抽样概率的条件下,当代理标签存在偏差时,偏差校正的伪结果是否能产生一致且渐近正态的估计?
- RQ3在不同社会科学数据集上,DSL 与 SO、GSO、SL 在偏差、覆盖率和 RMSE 的对比如何?
- RQ4该方法是否可以扩展到超越逻辑回归的广义矩估计量?
主要发现
- 在使用带有偏差校正伪结果的代理标签时,DSL 能为下游回归系数提供一致性和渐近正态性。
- DSL 的方差估计量是一致的,在不要求正确指定代理模型的情况下也能给出有效的置信区间。
- 即使代理标签任意偏差,DSL 仍然有效,前提是已知金标准标注的概率且与零有界距离。
- 18个数据集的实证结果显示 DSL 具有低偏差和名义上或接近名义的覆盖率,RMSE 与以预测为焦点的替代方法相当,优于仅金标准基线。
- 代理标签的准确性提高(例如更多的后 LLM 提示)会提升 DSL 的效率,当代理标签质量更高时,RMSE 的提升更大。
- 该框架支持多重代理并扩展到基于设计的矩,便于广泛应用于常见的社会科学估计量。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。