[论文解读] V2X-Boosted Federated Learning for Cooperative Intelligent Transportation Systems with Contextual Client Selection
本文提出一个四阶段的上下文客户端选择管线用于车载网络中的联邦学习,利用V2X数据预测未来网络时延,对客户端进行按数据分布聚类,并选择低时延客户端以在非IID设定下提升FL性能。
Machine learning (ML) has revolutionized transportation systems, enabling autonomous driving and smart traffic services. Federated learning (FL) overcomes privacy constraints by training ML models in distributed systems, exchanging model parameters instead of raw data. However, the dynamic states of connected vehicles affect the network connection quality and influence the FL performance. To tackle this challenge, we propose a contextual client selection pipeline that uses Vehicle-to-Everything (V2X) messages to select clients based on the predicted communication latency. The pipeline includes: (i) fusing V2X messages, (ii) predicting future traffic topology, (iii) pre-clustering clients based on local data distribution similarity, and (iv) selecting clients with minimal latency for future model aggregation. Experiments show that our pipeline outperforms baselines on various datasets, particularly in non-iid settings.
研究动机与目标
- 解决C-ITS(协同 ITS)中联邦学习的数据与网络异质性。
- 利用V2X消息预测未来网络时延和路况拓扑。
- 按局部数据分布相似性对客户端进行聚类,以降低非IID效应。
- 选择具有代表性且低时延的客户端,以提高聚合效率和收敛性。
提出的方法
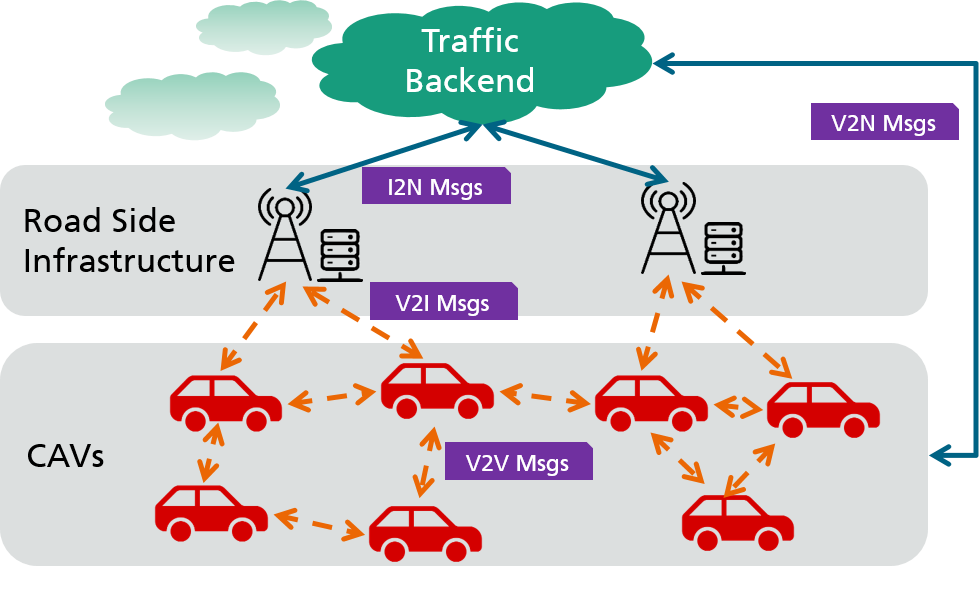
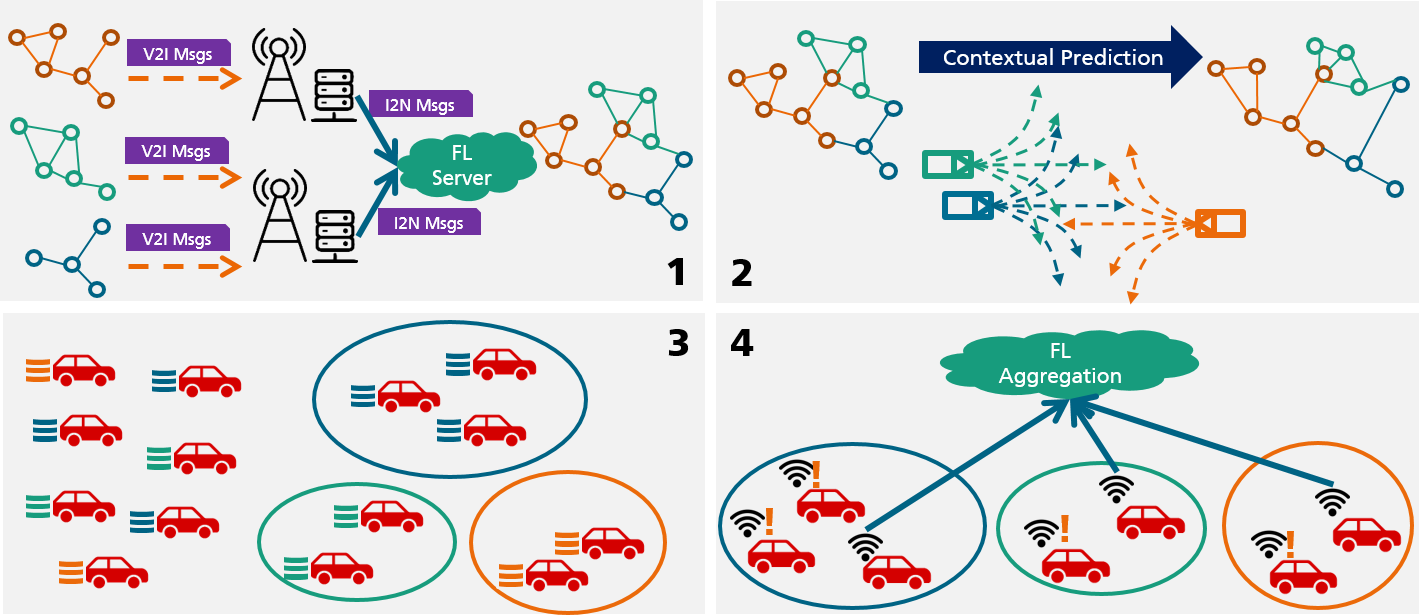
- 融合CAM/CPM V2X消息,构建道路交通拓扑图(RTTG)。
- 预测未来RTTG以估计即将轮次中各客户端的连接质量。
- 利用梯度/参数相似性按数据分布相似性对客户端进行分组以实现数据层聚类。
- 使用预测的RTTG时延和快速伽玛(Fast-gamma)规则,在每个簇中选择一小组低时延客户端进行聚合。
- 在分布于100辆车的非IID MNIST、CIFAR-10 和 SVHN 上评估该方法,并与贪婪、 gossip、基于数据 和 基于网络 的基线进行比较。
实验结果
研究问题
- RQ1如何融合并利用V2X信息来预测车载网络中联邦学习的未来网络时延?
- RQ2在CAVs中存在的非IID数据下,数据层和网络层的上下文客户端选择能否提升FL性能?
- RQ3在准确性、收敛和通信效率方面,上下文选择框架与标准基线相比如何?
- RQ4该方法对变化的网络连接率和数据异质性是否鲁棒?
主要发现
- 在非IID设定下,情境化客户端选择在MNIST、CIFAR-10和SVHN上优于四个基线(贪婪、 gossip、基于数据、基于网络)。
- 该方法实现更快的收敛,在不同连接速率下,与基线相比,达到0.5精度的时间缩短超过20倍。
- 即使存在数据异质性,该方法也比基于网络的策略具有更稳定的收敛性。
- 在连接客户端比例低至20%时,性能增益依然保持。
- 实验显示测试准确率持续更高且对非IID数据分布具有鲁棒性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。