[论文解读] VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
VASA-1 能在实时从单张图像生成高保真、以音频驱动的对话人脸视频,产生同步的唇部运动、富有表情的面部动态和自然的头部运动。它在一个解耦的人脸潜在空间中使用扩 diffusion-based holistic facial dynamics model in a disentangled face latent space.
We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only generating lip movements that are exquisitely synchronized with the audio, but also producing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos. Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method not only delivers high video quality with realistic facial and head dynamics but also supports the online generation of 512x512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
研究动机与目标
- Motivate realistic, audio-driven talking face generation beyond lip synchronization.
- Develop a disentangled, expressive face latent space for holistic facial dynamics and head motion.
- Enable real-time generation with high visual quality and controllable signals (gaze, distance, emotion).
- Leverage diffusion transformers to model audio-conditioned facial dynamics in latent space.
提出的方法
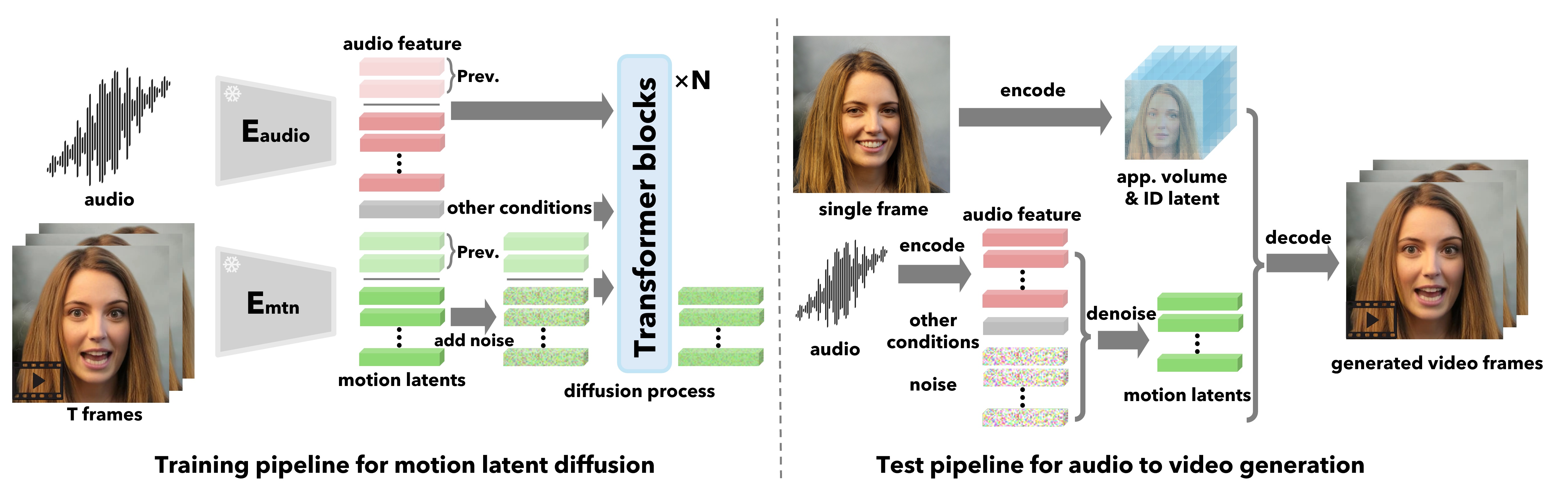
- Build a 3D-aided, disentangled face latent space with components V_app, z_id, z_pose, z_dyn.
- Train a diffusion transformer to model identity-agnostic holistic facial dynamics and head motion from audio features.
- Use a conditional diffusion framework with optional controls (gaze g, distance d, emotion e) and classifier-free guidance for stable sampling.
- Decode motion latent codes into video frames via a face decoder using appearance and identity features from the input image.
- Train on large-scale talking-face videos (VoxCeleb2 and extra high-res dataset) to achieve expressive, controllable outputs.

实验结果
研究问题
- RQ1Can holistic, identity-agnostic facial dynamics in a latent space be effectively modeled to produce synchronized lip movements and natural head pose from audio?
- RQ2Does a diffusion-transformer-based approach outperform prior methods in lip-audio synchronization, pose alignment, and overall video quality?
- RQ3How do controllable signals (gaze, head distance, emotion) affect realism and controllability of generated talking faces?
- RQ4What is the impact of sampling steps and CFG scales on lip-audio synchronization, pose accuracy, and video quality?
主要发现
- Outperforms prior methods on both lip synchronization and pose alignment metrics across VoxCeleb2 and OneMin-32 benchmarks.
- Audio-lip synchronization scores: Ours achieve S_C=8.841 and S_D=6.312 on VoxCeleb2, with CAPP=0.468 and ΔP=0.304 on OneMin-32.
- CAPP metric correlates with audio-pose alignment and degrades with frame shifts, demonstrating robust evaluation of audio-head pose synchronization.
- CFG tuning (audio CFG λ_A=0.5 and gaze CFG λ_g=1.0) improves lip-audio alignment and pose synchronization; sampling steps trade off speed and quality (fewer steps speed up inference).
- Video quality (FVD_25) is significantly better than baselines; OneMin-32 shows FVD_25=105.884 for the proposed method vs real video 29.244, indicating higher realism in generated sequences.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。