[论文解读] VerilogEval: Evaluating Large Language Models for Verilog Code Generation
论文介绍 VerilogEval,一个专注于 Verilog 的基准测试(156 个 HDLBits 问题),用于评估大语言模型在 Verilog 代码生成上的能力,包括一个自动化测试管线和用于提升性能的合成有监督微调数据。
The increasing popularity of large language models (LLMs) has paved the way for their application in diverse domains. This paper proposes a benchmarking framework tailored specifically for evaluating LLM performance in the context of Verilog code generation for hardware design and verification. We present a comprehensive evaluation dataset consisting of 156 problems from the Verilog instructional website HDLBits. The evaluation set consists of a diverse set of Verilog code generation tasks, ranging from simple combinational circuits to complex finite state machines. The Verilog code completions can be automatically tested for functional correctness by comparing the transient simulation outputs of the generated design with a golden solution. We also demonstrate that the Verilog code generation capability of pretrained language models could be improved with supervised fine-tuning by bootstrapping with LLM generated synthetic problem-code pairs.
研究动机与目标
- 通过利用 HDLBits 问题并设定明确的正确性标准,激发一个面向 Verilog 代码生成的领域特定基准。
- 提供一个自动化测试环境,以评估所生成 Verilog 代码的功能正确性。
- 展示由 LLMs 生成的合成有监督微调数据能够提升 Verilog 编码性能。
- 调查模型规模和基础模型如何影响 Verilog 编码能力与 SFT 的有效性。
提出的方法
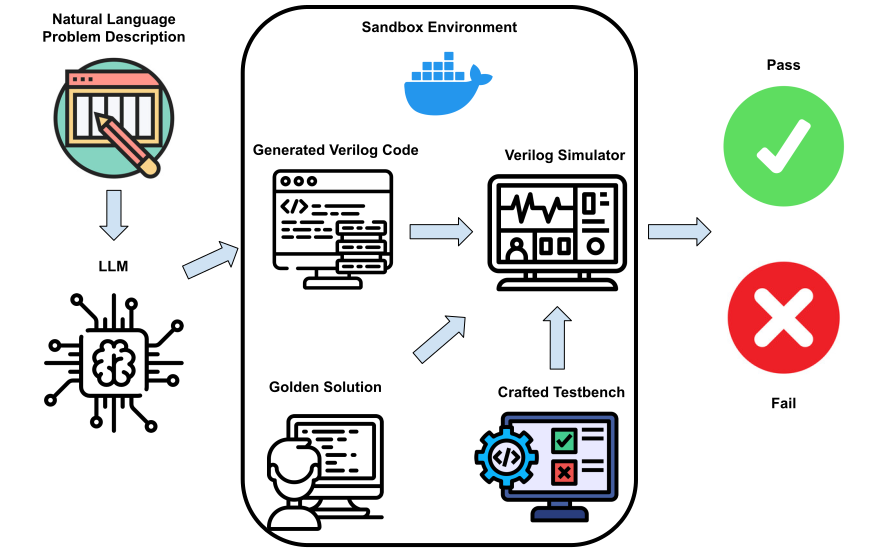
- 构建一个沙盒式评估框架,仿照 HumanEval 的模式用于 Verilog 代码生成。
- 从 HDLBits 收集自包含模块,组装一个含 156 道题目的 Verilog 评估集合。
- 通过在 Docker 沙盒中的 ICARUS Verilog 进行功能仿真,自动用黄金解来测试生成的 Verilog 补全。
- 通过从 GitHub 提取自包含的 Verilog 模块、由 LLMs 生成描述性文本,并将描述与代码配对,创建一个合成的 SFT 数据集。
- 在合成 SFT 数据上微调 CodeGen 家族模型,并使用 pass@k 指标评估(k ∈ {1,5,10})。
- 对比 GPT-3.5/4 与 Verilog 相关的基础模型(codegen-nl、codegen-multi、codegen-Verilog)的性能,并分析数据质量的影响。
实验结果
研究问题
- RQ1LLMs 是否能够从自然语言描述可靠地生成正确的 Verilog 代码,覆盖多样化任务?
- RQ2沙盒化、自动化测试工作流是否与 Verilog 解决方案的功能正确性相关?
- RQ3在微调 LLMs 时,合成 SFT 数据在多大程度上可以提升 Verilog 代码生成?
- RQ4模型规模和基础模型选择如何影响 VerilogEval 的性能?
- RQ5SFT 数据质量对后续 Verilog 编码性能的影响是什么?
主要发现
- VerilogEval 表明可以通过与黄金解的自动仿真来衡量功能正确性。
- 更大、更有能力的模型通常在 Verilog 编码上表现更好。
- 合成的 SFT 数据在 Verilog 训练和部分多语言基础模型上提升下游 Verilog 性能,对 VerilogEval-machine 结果尤其显著。
- SFT 数据质量很重要:引入错误的问题-代码对会降低性能,凸显高质量合成数据的重要性。
- GPT-4 在多种配置下在 pass@1、pass@5、pass@10 上都高于 GPT-3.5,且在某些基线下,Verilog-focused SFT 的表现可接近 GPT-3.5。
- SFT 存在权衡:增加训练轮数可以提升 pass@1,但可能因对 SFT 数据过拟合而降低 pass@5 和 pass@10。
![Figure 7: Variance in estimating pass@ k with $n$ . Samples from codegen-16B-verilog [ 12 ] for VerilogEval-human .](https://ar5iv.labs.arxiv.org/html/2309.07544/assets/figs/variance.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。