[论文解读] Video Anomaly Detection in 10 Years: A Survey and Outlook
本综述回顾基于深度学习的视频异常检测(VAD),包括监督、弱监督、自监督、无监督方法,以及视觉-语言模型,并讨论数据集、损失函数与未来方向。
Video anomaly detection (VAD) holds immense importance across diverse domains such as surveillance, healthcare, and environmental monitoring. While numerous surveys focus on conventional VAD methods, they often lack depth in exploring specific approaches and emerging trends. This survey explores deep learning-based VAD, expanding beyond traditional supervised training paradigms to encompass emerging weakly supervised, self-supervised, and unsupervised approaches. A prominent feature of this review is the investigation of core challenges within the VAD paradigms including large-scale datasets, features extraction, learning methods, loss functions, regularization, and anomaly score prediction. Moreover, this review also investigates the vision language models (VLMs) as potent feature extractors for VAD. VLMs integrate visual data with textual descriptions or spoken language from videos, enabling a nuanced understanding of scenes crucial for anomaly detection. By addressing these challenges and proposing future research directions, this review aims to foster the development of robust and efficient VAD systems leveraging the capabilities of VLMs for enhanced anomaly detection in complex real-world scenarios. This comprehensive analysis seeks to bridge existing knowledge gaps, provide researchers with valuable insights, and contribute to shaping the future of VAD research.
研究动机与目标
- 识别现代 VAD 的核心挑战,包括大规模数据集、特征提取、损失函数、正则化和异常分数预测。
- 评估深度学习方法(监督、弱监督、自监督、无监督)对 VAD 性能的影响。
- 探索 vision-language 模型作为 VAD 的特征提取器的潜力。
- 综合数据集基准并提供建议以指导未来的 VAD 研究与实践。
提出的方法
- 对过去十年来自顶级计算机视觉会议(CVPR、ICCV、ECCV、TPAMI、IJCV、CVIU)的文献进行系统性综述。
- 将方法分为监督、无监督、自监督和弱监督类别。
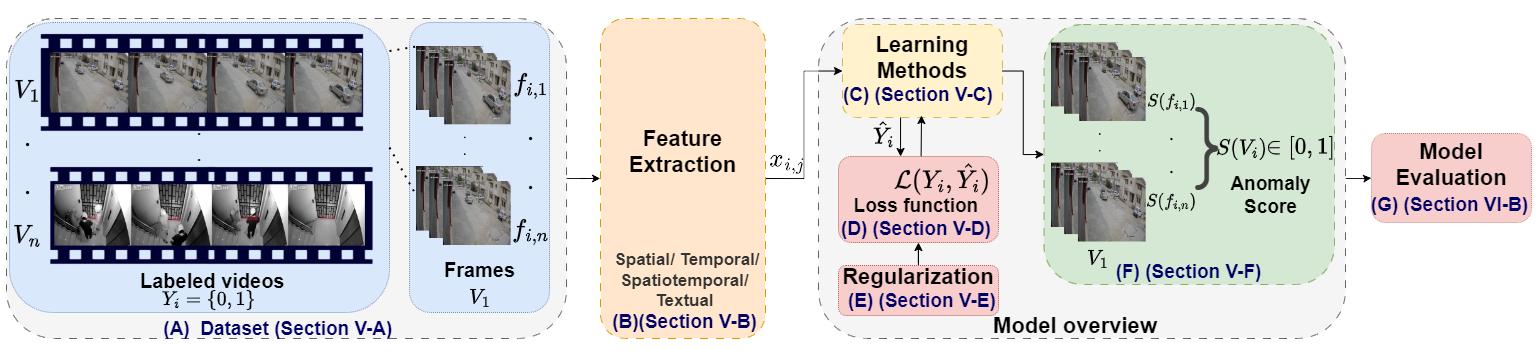
- 分析数据集、特征提取技术(空间、时间、时空、文本),以及损失/正则化方案。
- 在基准数据集上评估最先进模型(定性与定量)以识别优点与弱点。
- 讨论 vision-language 模型(VLMs)作为 VAD 的特征提取器及其对性能的影响。
- 提出未来方向与对鲁棒 VAD 系统的建议。
![Figure 1: Performance improvement from 2017 until 2023 on two popular benchmarks. Performance is measured by the area under the ROC curve (AUC%). Note that some of the models were developed before the datasets were created but were used after the creation by other researchers such as [ 15 , 16 ] . T](https://ar5iv.labs.arxiv.org/html/2405.19387/assets/Figures/introchart.png)
实验结果
研究问题
- RQ1用于视频异常检测的主流深度学习范式有哪些(监督、弱监督、自监督、无监督),它们之间有何差异?
- RQ2特征提取选择(空间、时间、时空、文本)和损失函数如何影响 VAD 性能?
- RQ3视觉-语言模型在 VAD 中的作用是什么,它们如何影响异常分数预测与定位?
- RQ4哪些数据集和评估协议能最好地体现现实世界的 VAD 挑战,基准应如何演变?
- RQ5哪些未来方向可以解决 VAD 目前的局限性(数据多样性、现实性、长期上下文、多模态数据)?
主要发现
- 基于深度学习的 VAD 在过去十年显著提升了性能,视觉-语言模型带来了显著收益。
- 数据集在复杂性和真实性方面各不相同,诸如异常多样性有限和类别不平衡等问题被指出为挑战。
- 空间和时间特征都是必不可少的;将它们整合到时空表征中可提升检测与定位。
- 弱监督和无监督范式在降低标注负担的同时保持鲁棒检测方面越来越重要。
- 视觉-语言特征提供互补的语义上下文,可增强对异常的理解与评分。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。